Kafka Architecture: Diagram & Components
Kafka's architecture is a distributed commit log: producers append records to topics, brokers store those records in partitioned, replicated logs across a cluster, and consumers read from those logs independently at their own pace. This decoupled, durable design lets a single cluster serve high-throughput writes and reads simultaneously while surviving individual broker failures without data loss.
High-Level Architecture
At the top level, a Kafka cluster has three categories of participant:
- Producers: applications that write records to topics
- Brokers: servers that store partition replicas and serve requests
- Consumers: applications (organized into consumer groups) that read records from topics
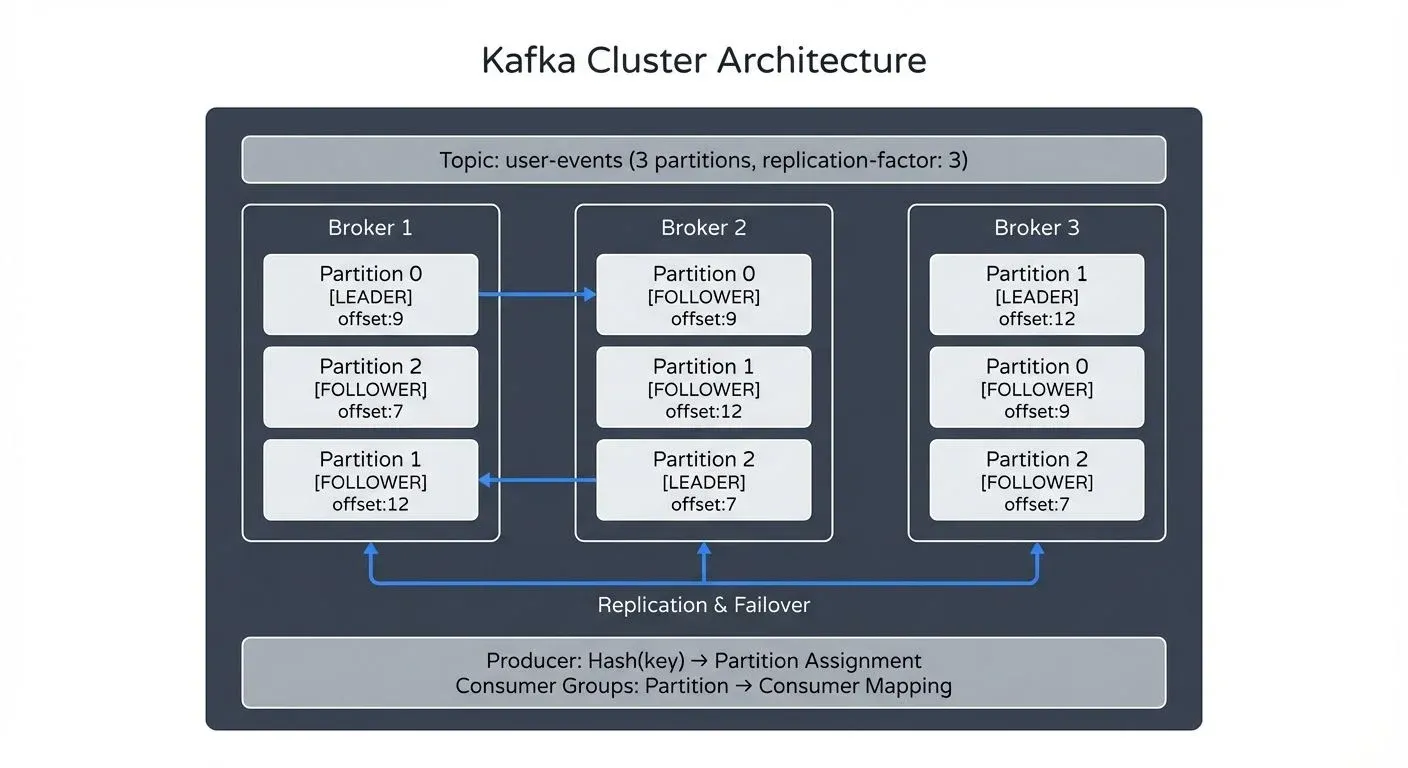
The cluster itself is coordinated by a controller, in Kafka 4.0+ this is a KRaft controller quorum, not ZooKeeper. The controller tracks which broker leads each partition, handles partition leadership elections on broker failure, and stores all cluster metadata.
Core Components
Topics
A topic is a named, append-only log. It is the primary abstraction that producers and consumers interact with. Every record belongs to a topic. Topics are retained independently of consumption, consumers can replay past records by resetting their offset.
Key properties:
- Schema-agnostic: brokers store raw bytes
- Multi-subscriber: any number of consumer groups can read the same topic independently
- Configurable retention: time-based (
retention.ms) or size-based (retention.bytes)
Partitions
A partition is the physical unit of a topic, an ordered, immutable sequence of records on a single broker's local disk. Every topic has one or more partitions.
Partitions serve two purposes:
- Parallelism: each partition is consumed by at most one consumer per group at a time, so partition count caps maximum consumer parallelism
- Distribution: partitions are spread across brokers, distributing I/O and storage load
Within a partition, records have a monotonically increasing offset, the mechanism consumers use to track their position.
Brokers
A broker is a Kafka server. It stores partition replicas on local disk, handles producer write requests, serves consumer fetch requests, and participates in replication.
Multiple brokers form a cluster. Kafka distributes partition leaders across brokers so that no single broker bears the full write load.
KRaft Controllers
Since Kafka 4.0 (available since 3.3, GA in 3.5), the cluster controller uses KRaft, Kafka's own Raft-based consensus protocol, to store and manage metadata. Controller nodes (which may be the same as broker nodes in combined mode) form a quorum and store cluster state in an internal __cluster_metadata topic.
The controller is responsible for:
- Assigning partitions to brokers at topic creation
- Electing new partition leaders when a broker fails
- Tracking ISR (in-sync replica) membership per partition
- Persisting topic configuration, ACLs, and broker registrations
Data Flow: End to End
Producer → [hash(key) % partitions] → Partition Leader (Broker N)
↓ replicate
Followers (Broker M, Broker P)
↓
Consumer Group (reads from leader)- Producer sends a record with an optional key. If a key is present, Kafka hashes it to select the target partition, ensuring all records with the same key land in the same partition (ordering guarantee). Without a key, the producer round-robins across partitions.
- Partition leader (the broker leading that partition) receives the record, appends it to the local log, and, depending on the
ackssetting, waits for follower acknowledgment before responding to the producer. - Follower brokers pull new records from the leader and append to their local replica log. Followers that stay within
replica.lag.time.max.msremain in the ISR. - Consumer in a consumer group is assigned a subset of partitions by the group coordinator. It polls the partition leader for new records, processes them, and commits its offset back to Kafka (stored in the
__consumer_offsetsinternal topic).
Partition Replication Layout
For a 3-partition topic with replication-factor 3 across 3 brokers, Kafka spreads leadership and replicas evenly:
Partition 0: Leader=Broker 1 │ Followers=Broker 2, Broker 3
Partition 1: Leader=Broker 2 │ Followers=Broker 1, Broker 3
Partition 2: Leader=Broker 3 │ Followers=Broker 1, Broker 2If Broker 1 fails, Broker 2 or 3 (whichever is in the ISR for partition 0) is elected leader by the KRaft controller. Producers and consumers discover the leadership change via metadata refresh and reconnect, typically within seconds.
KRaft Architecture (Kafka 4.0+)
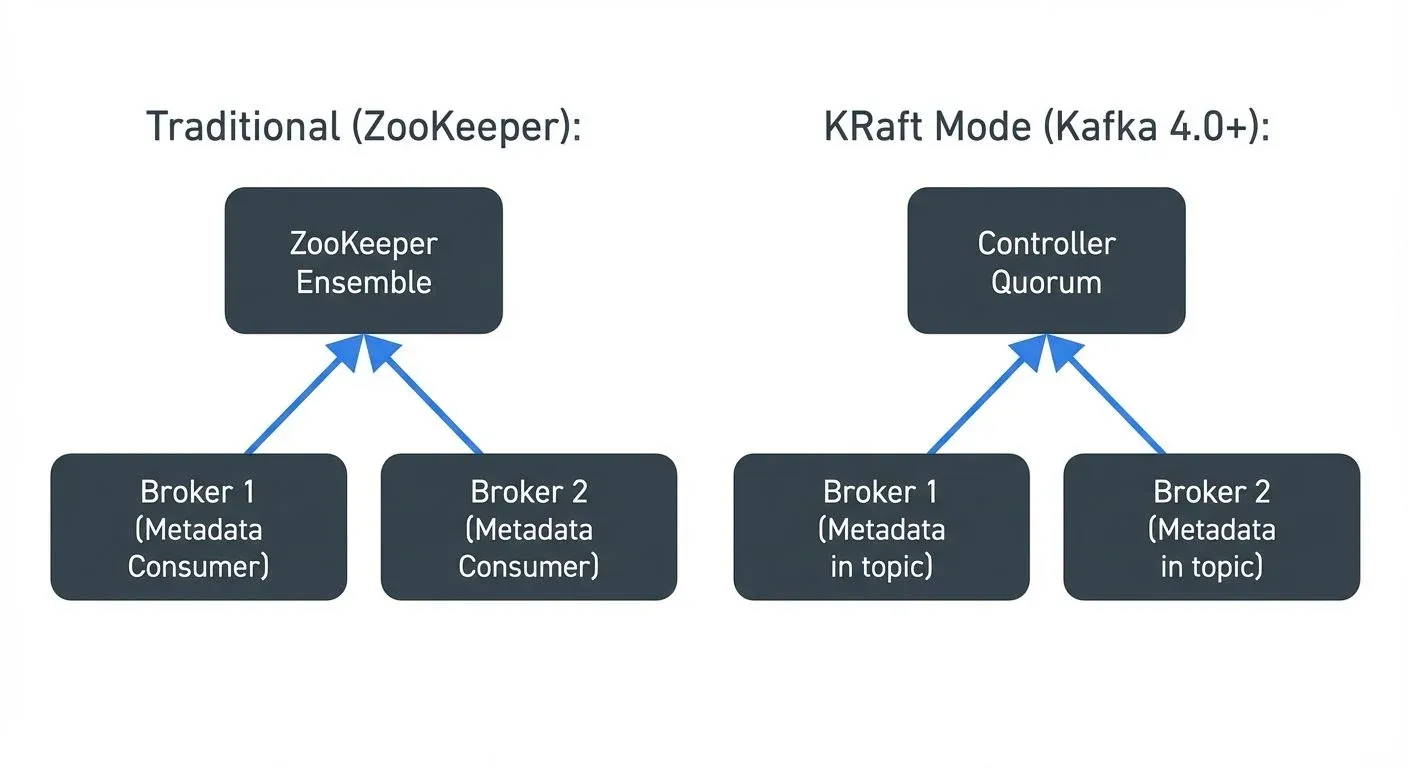
Before KRaft, Kafka relied on an external ZooKeeper ensemble for metadata coordination. ZooKeeper was a separate cluster to manage, monitor, and upgrade, and it capped practical cluster size at around 200K partitions.
KRaft replaces this with an internal Raft quorum of controller nodes. Benefits:
| ZooKeeper mode | KRaft mode (4.0+) | |
|---|---|---|
| Controller election | Seconds | Milliseconds |
| Max partitions | ~200K | Millions |
| External dependency | ZooKeeper cluster | None |
| Metadata storage | ZooKeeper znodes | __cluster_metadata topic |
| Auth model | Split (ZK + Kafka) | Unified |
See Understanding KRaft Mode in Kafka for migration and configuration details.
Tiered Storage Architecture (Kafka 3.6+)
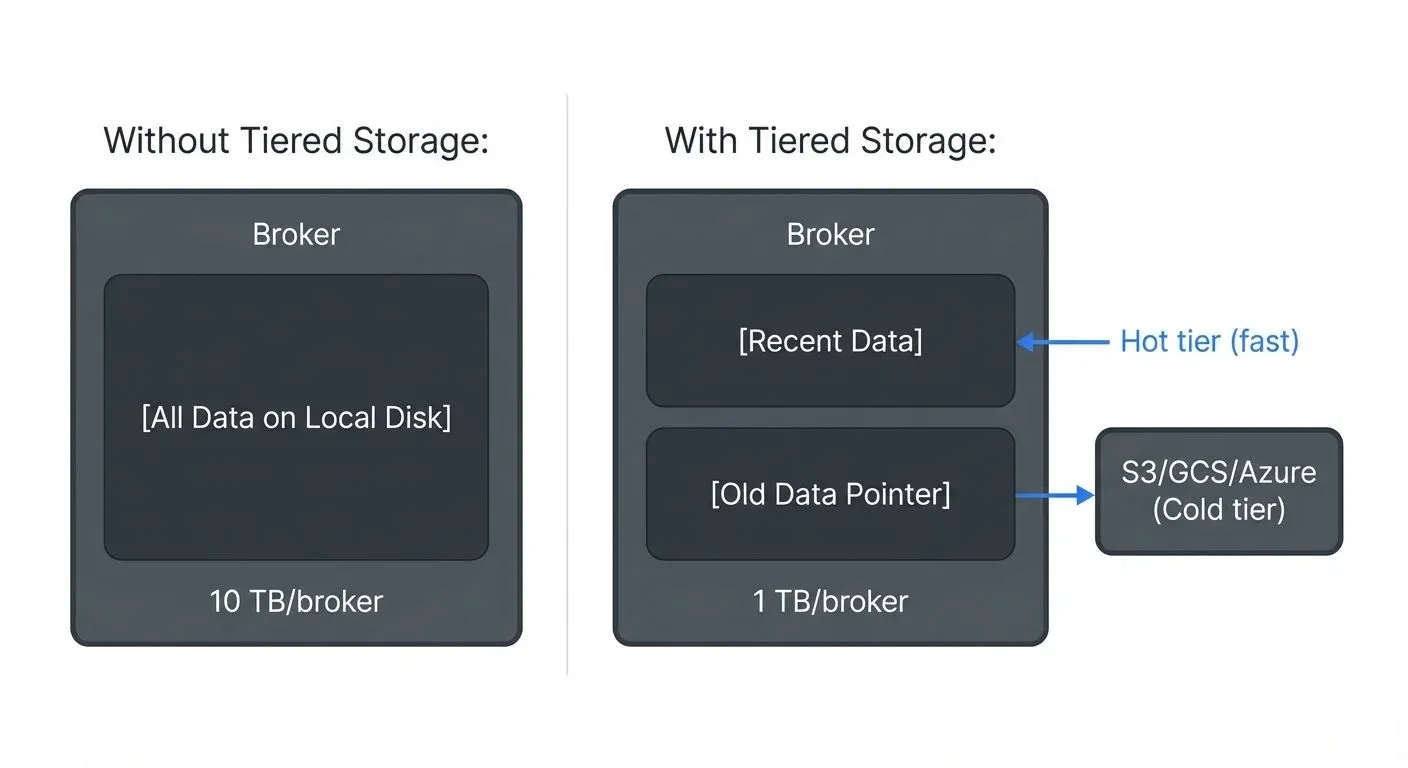
Kafka 3.6 introduced tiered storage, decoupling data retention from broker disk capacity:
- Hot tier: recent log segments on broker local disk, low latency, fast access
- Cold tier: older segments offloaded to object storage (S3, GCS, Azure Blob Storage), ~90% cheaper per GB than local disk
Consumers are unaware of which tier serves their request. The broker transparently fetches cold segments from object storage and streams them to the consumer.
This enables months or years of retention without scaling broker disk proportionally. Before tiered storage, a 90-day retention window required 90 days of data on every broker disk.
For configuration and best practices, see Tiered Storage in Kafka.
Architecture Enabling Properties
The combination of topics, partitions, brokers, and KRaft gives Kafka its core guarantees:
| Property | Mechanism |
|---|---|
| Horizontal scalability | Add brokers; reassign partitions to distribute load |
| Fault tolerance | Partition replication; ISR-based leader election |
| Per-key ordering | Key-based partition routing; per-partition ordering |
| Independent consumption | Each consumer group tracks its own offsets |
| Replay | Retention-based log; consumers can reset offsets |
| High throughput | Sequential disk I/O; batching; compression |
Kafka in the Streaming Ecosystem
Kafka's architecture makes it the hub of modern data platforms:
- Stream processing: Kafka Streams, Apache Flink, and Apache Spark Structured Streaming consume topics, transform records, and write to output topics
- Data integration: Kafka Connect moves data between Kafka topics and external systems (databases, S3, Elasticsearch)
- Event-driven microservices: services publish domain events to topics and subscribe to events from other services
- Analytics pipelines: operational topics feed data lakes and warehouses via connectors or stream processors
For more on Kafka's role in data platforms, see Apache Kafka and Kafka Producers and Consumers.
Related Pages
- What is a Kafka Topic?, the logical stream abstraction
- What is a Kafka Partition?, ordering, parallelism, and replication unit
- What is a Kafka Broker?, storage, replication, and client request handling
- Understanding KRaft Mode in Kafka, controller quorum deep dive
- Kafka Replication and High Availability, ISR, failover, and durability
- Tiered Storage in Kafka, separating hot and cold storage
- Kafka Consumer Groups Explained, partition assignment and offset management
- Kafka Producers and Consumers, how records are written and read