Kafka Producers and Consumers
Apache Kafka is designed as a distributed, fault-tolerant commit log. While Kafka brokers manage storage and replication, the actual transfer of data relies on two critical client components: producers and consumers. These client applications determine the data quality, latency, throughput, and reliability of modern data streaming architectures.
Understanding how producers and consumers work, their configuration options, delivery guarantees, and operational characteristics, is essential for building scalable, reliable streaming systems. For foundational architecture concepts, see Apache Kafka and Kafka Topics, Partitions, Brokers: Core Architecture. 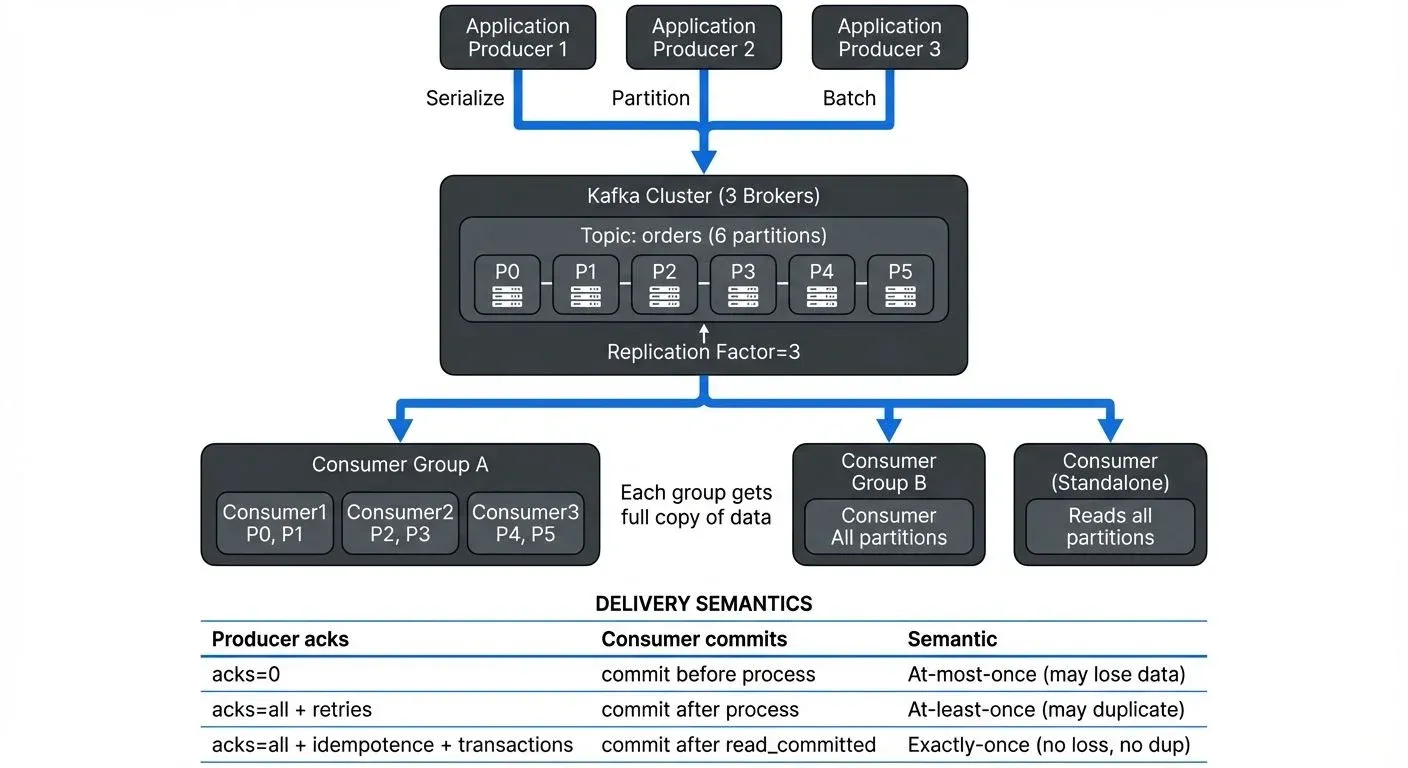
Producers and Consumers: The Communication Protocol
Kafka producers and consumers are core client applications that mediate the flow of data between application layers and the Kafka cluster. They interact using the Kafka protocol, which enables a completely asynchronous and decoupled architecture.
A producer is an application that serializes and writes records (messages) to a Kafka topic. Producers are responsible for converting application data structures into bytes, determining which partition receives each record, and managing delivery guarantees through configurable acknowledgment mechanisms.
A consumer is an application that reads records sequentially from Kafka topic partitions. Consumers track their reading position through offsets, can operate independently or as part of a consumer group for parallel processing, and control when to commit their progress back to Kafka.
This decoupling is fundamental: producers don't need to know who is consuming the data, and consumers don't need to know who produced it. This separation allows applications to scale independently, evolve at different rates, and recover from failures without affecting each other.
How Kafka Producers Work: Record Delivery and Guarantees
The producer is responsible for reliably packaging, routing, and delivering messages to the appropriate Kafka topic partition.
Producer Responsibilities
- Serialization: Producers convert application data structures (JSON objects, Avro records, Protobuf messages) into byte arrays before sending them over the network. A Kafka record consists of a key (optional), value, headers (optional metadata), and timestamp. Common serializers include StringSerializer, ByteArraySerializer, and schema-aware serializers like Avro or Protobuf that integrate with Schema Registry for structured data validation. For detailed coverage of serialization formats and trade-offs, see Message Serialization in Kafka and Schema Registry and Schema Management.
- Partitioning: Producers determine which partition receives each record. If a key is provided, Kafka uses consistent hashing to map the key to a partition:
partition = hash(key) % number_of_partitionsThis ensures all records with the same key go to the same partition, preserving ordering for that key. If no key is specified, the default partitioner (since Kafka 2.4+) uses a sticky partitioning strategy, filling batches by sending records to the same partition until the batch is full, then switching to another partition. This "sticky" behavior significantly improves throughput by creating larger, more efficient batches compared to round-robin partitioning, which scattered records across all partitions and created many small batches.
Buffering and Batching: Producers don't send records individually. Instead, they accumulate records in memory buffers and send them to brokers in efficient batches, significantly improving throughput by amortizing network and disk I/O overhead.
Key batching configurations include:
batch.size: Maximum bytes per batch (default: 16 KB)linger.ms: Maximum time to wait before sending a batch (default: 0)
Setting linger.ms to 5-10 milliseconds allows the producer to collect more records per batch, increasing throughput with minimal latency impact. Producers can also compress batches using algorithms like gzip, snappy, lz4, or zstd.
Delivery Semantics and Acknowledgments
A critical configuration is the acknowledgment (acks) setting, which determines the delivery guarantee:
- acks=0 (At-Most-Once): Producer doesn't wait for any acknowledgment from brokers. This provides the fastest throughput but risks data loss if the broker fails before persisting the record.
- acks=1 (At-Least-Once): Producer waits for the leader partition replica to acknowledge the write. This guarantees delivery but may result in duplicate records if the producer retries after a network failure and the original write actually succeeded.
- acks=all or -1 (Exactly-Once Foundation): Producer waits for acknowledgment from all in-sync replicas (ISRs). Since Kafka 3.0+, idempotent producers are enabled by default (
enable.idempotence=true), which effectively requiresacks=allfor data safety. Combined with transactional IDs, this enables exactly-once processing, ensuring records are written once and only once, even after failures.
For critical data, use acks=all combined with min.insync.replicas=2 to ensure at least one replica has received the data before acknowledgment, protecting against data loss.
Example Producer Configuration (Java)
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
// Modern production settings (Kafka 3.0+)
props.put("acks", "all");
props.put("enable.idempotence", "true"); // Default since 3.0+
props.put("compression.type", "lz4");
props.put("batch.size", 32768); // 32 KB batches
props.put("linger.ms", 10); // Wait up to 10ms for batching
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
// Send asynchronously with callback
producer.send(new ProducerRecord<>("orders", "key123", "order data"),
(metadata, exception) -> {
if (exception != null) {
// Handle send failure
} else {
// Record sent to partition metadata.partition() at offset metadata.offset()
}
});How Kafka Consumers Work: Tracking Progress with Offsets
Consumers read records from Kafka partitions by subscribing to one or more topics and pulling data from assigned partitions. Unlike push-based messaging systems, Kafka's pull model allows consumers to control their read rate and handle backpressure naturally. For strategies on managing consumer processing rates, see Backpressure Handling in Streaming Systems.
Sequential Reading and Offset Management
Consumers read records sequentially based on their offset within a partition, a monotonically increasing identifier that serves as the consumer's position in the log. Each partition maintains its own offset sequence independently.
- Offset Commitment: A consumer periodically commits its latest successfully processed offset back to Kafka, specifically to an internal topic named
__consumer_offsets. This commit serves as a checkpoint, indicating which records have been successfully processed. In Kafka 4.0+ with KRaft mode (Kafka's ZooKeeper-free architecture), offset management remains identical from a client perspective, but the underlying coordination is handled by Kafka's internal Raft-based consensus protocol. For details on KRaft's architecture, see Understanding KRaft Mode in Kafka. - Failure Recovery: If a consumer instance fails or restarts, it retrieves the last committed offset from
__consumer_offsetsand resumes reading from the next record. This ensures continuous processing, though it may result in reprocessing records if the consumer failed between processing and committing.
Offset commits can be:
- Automatic (
enable.auto.commit=true): Commits occur at regular intervals configured byauto.commit.interval.ms(default: 5 seconds). Simple to implement but may cause duplicate processing if the consumer fails between the automatic commit and actual record processing. - Manual: Application explicitly commits after successfully processing records, providing precise control over delivery semantics.
Example Consumer Configuration (Java)
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "order-processing-group");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
// Modern production settings
props.put("enable.auto.commit", "false"); // Manual commit for precise control
props.put("max.poll.records", 500); // Process up to 500 records per poll
props.put("partition.assignment.strategy", "org.apache.kafka.clients.consumer.CooperativeStickyAssignor"); // Incremental cooperative rebalancing
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("orders"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
// Process record
processOrder(record.value());
}
// Commit offsets after successful processing
consumer.commitSync();
}Consumer Groups: Scaling Read Concurrency
A consumer group is a set of consumers that share a common group.id. For a given topic, the partitions are divided among the consumer instances in that group, enabling parallel processing while maintaining order within each partition.
- Exclusive Partition Access: Each partition is assigned to exactly one consumer instance within the group at any time. This prevents duplicate processing within the group and ensures each record is processed by only one consumer.
- Rebalancing: When a consumer instance joins or leaves a group (due to scaling, failure, or deployment), or if the topic's partitions change, a group rebalance occurs. The partitions are redistributed among active members, ensuring high availability.
Since Kafka 2.4+, incremental cooperative rebalancing is the default protocol (replacing the older eager rebalancing). With cooperative rebalancing, consumers only give up partitions that need to be reassigned, continuing to process their remaining partitions during the rebalance. This significantly reduces processing interruptions compared to eager rebalancing, where all consumers stopped processing until the rebalance completed.
For example, if a topic has six partitions and a consumer group has three consumers, each consumer handles two partitions. Adding a fourth consumer triggers a rebalance, redistributing partitions so each consumer handles 1-2 partitions. However, adding more consumers beyond the partition count provides no additional concurrency, extra consumers remain idle.
Delivery Semantics: At-Most-Once, At-Least-Once, and Exactly-Once
Kafka supports three delivery guarantee models, each representing different trade-offs between reliability, performance, and complexity.
At-Most-Once
Records may be lost but are never duplicated. Achieved by:
- Producer:
acks=0oracks=1without retries - Consumer: Commit offsets before processing records
Provides maximum throughput and lowest latency but risks data loss. Suitable for non-critical telemetry or monitoring data where occasional loss is acceptable.
At-Least-Once
Records are never lost but may be processed multiple times. Achieved by:
- Producer:
acks=allwith retries enabled - Consumer: Commit offsets after successfully processing records
Most common semantic in production systems, ensuring no data loss. Applications must implement idempotent processing logic to handle potential duplicates correctly.
Exactly-Once
Records are delivered and processed exactly once, even during failures. Kafka achieves this through:
- Idempotent producers (
enable.idempotence=true): Prevents duplicate writes during retries - Transactional producers: Atomic writes across multiple partitions
- Transactional consumers: Read only committed messages (
isolation.level=read_committed)
Exactly-once semantics require careful configuration but provide the strongest guarantees for financial transactions, inventory updates, or billing systems where duplicates or data loss cause incorrect results. For comprehensive coverage of transactional mechanics, see Kafka Transactions Deep Dive.
Producers and Consumers in Streaming Architectures
The producer-consumer model powers real-time data pipelines and advanced stream processing across modern architectures:
- Change Data Capture Pipelines: Tools like Debezium act as specialized producers (Kafka Connect Source Connectors), continuously capturing database change events and writing them into Kafka topics, enabling real-time replication and analytics. For detailed coverage of CDC patterns, see What is Change Data Capture (CDC) Fundamentals.
- Stream Processing Engines: Frameworks like Apache Flink and Kafka Streams are built on the consumer API. They read records from topics, perform complex stateful transformations (aggregations, joins, windowing), and write results back using the producer API.
- Sink Connectors and Data Integration: Kafka Connect Sink Connectors act as specialized consumers, reliably reading data from topics and writing it to final destinations like data warehouses (Snowflake, BigQuery), search indexes (Elasticsearch), or cloud storage (S3).
- Microservices Communication: Services act as both producers and consumers, publishing domain events to topics and subscribing to events from other services. This event-driven architecture decouples services while maintaining consistency through event ordering and replay capabilities.
Monitoring, Troubleshooting, and Governance at Scale
As Kafka deployments grow, managing producer and consumer behavior becomes increasingly complex. Operational health monitoring must extend beyond Kafka brokers to the client applications themselves.
Key Operational Challenges
- Consumer Lag: The difference (in offsets or time) between the latest record written to a partition and the last record committed by a consumer group indicates processing delays. High consumer lag suggests consumers can't keep up, requiring optimization, additional consumer instances, or investigation of processing bottlenecks. Modern tools like Kafka Lag Exporter (with Prometheus/Grafana integration) provide automated lag monitoring and alerting. For comprehensive strategies and best practices, see Consumer Lag Monitoring.
- Producer Throughput and Error Rates: Monitoring producer metrics like record send rate, batch size, compression ratio, and network errors helps identify performance bottlenecks. Misconfigured batching, serialization failures, or broker unavailability can significantly impact pipeline reliability.
- Consumer Group State: Tracking group rebalancing frequency is essential, frequent rebalancing indicates instability due to consumer failures, network issues, or configuration problems. Each rebalance temporarily halts processing, impacting end-to-end latency.
Client Governance and Access Control
In enterprise environments, managing access for numerous client applications is a major governance challenge. Kafka uses ACLs (Access Control Lists) to manage permissions, allowing only specific client IDs to write to sensitive topics or limiting which consumer groups can read confidential data streams. For comprehensive security patterns and best practices, see Kafka Security Best Practices.
Without centralized governance, tracking producer and consumer activity becomes challenging. Questions like "Which applications are producing to this topic?", "Who's consuming this sensitive data?", and "Why is this consumer group lagging?" require manual investigation across application logs and metrics systems.
Platforms like Conduktor address these challenges by providing unified visibility and controls for Kafka environments. Teams can monitor consumer lag in real-time across all consumer groups, track which applications interact with each topic, enforce schema validation at the producer level, manage ACLs through a visual interface, and audit client access patterns for compliance. Learn how to manage topics and monitor consumer groups and configure service accounts with proper ACLs for secure access control. When troubleshooting lag spikes, Conduktor immediately identifies which partitions are falling behind, correlates this with producer throughput changes or rebalancing events, and alerts the responsible team, enabling faster root cause analysis while maintaining a complete audit trail. For advanced testing scenarios like chaos engineering and protocol manipulation, Conduktor Gateway provides proxy-based capabilities to validate producer and consumer resilience.
Related Concepts
- Kafka Consumer Groups Explained - Details how consumer groups coordinate partition assignment for parallel processing.
- Schema Registry and Schema Management - Essential for managing serialization formats used by producers and consumers.
- Consumer Lag Monitoring - Critical for detecting when consumers fall behind producers and ensuring pipeline health.
Summary
Kafka producers and consumers are the vital client-side components that implement the asynchronous and decoupled communication central to data streaming. Producers handle serialization, partition selection, batching, compression, and delivery guarantees through configurable acknowledgment mechanisms. Consumers coordinate through consumer groups to process partitions in parallel, manage offsets to track progress, and support multiple delivery semantics from at-most-once to exactly-once processing.
The producer-consumer model manages critical functions like message delivery guarantees, sequential processing with ordering preservation, and high-throughput concurrency via consumer groups. This architecture enables the decoupled, scalable patterns that power real-time data platforms, allowing multiple independent consumers to process the same data for different purposes, supporting microservices communication without tight coupling, and connecting directly with stream processing frameworks.
Teams focus on tuning client configuration parameters (acks, batch.size, linger.ms, auto.commit settings), implementing proper error handling and retry logic, aggressively monitoring client health, particularly consumer lag and producer error rates, and choosing appropriate delivery semantics based on data criticality. As deployments scale, proactive monitoring of client-side metrics becomes vital for detecting and resolving pipeline slowdowns.
Enterprise governance platforms provide the management layer for controlling and auditing which client applications have permission to produce or consume data, maintaining security and compliance. These tools offer centralized monitoring of consumer lag, tracking of producer and consumer activity per topic, schema validation enforcement, and visual ACL management, bridging the gap between Kafka's low-level client mechanics and enterprise operational requirements.
Sources and References
- Apache Software Foundation. Apache Kafka Documentation: Producer Configs
- Apache Software Foundation. Apache Kafka Documentation: Consumer Configs
- Confluent. Transactions in Apache Kafka (Exactly-Once Semantics)
- Confluent. Apache Kafka Producer and Consumer Fundamentals
- Debezium. Architecture Overview
Written by Stéphane Derosiaux · Last updated April 29, 2026