Semantic Layer for Streaming: Business Meaning for Real-Time Data
A data analyst joins a team and needs to calculate daily active users from real-time event streams. She discovers three different Kafka topics that seem relevant: user.events.v2, app_interactions, and user_activity_enriched. Each has different field names for user identifiers (user_id, userId, customer_key), different timestamp formats, and unclear definitions of what constitutes an "active" user.
This scenario repeats across organizations adopting streaming architectures. While Apache Kafka, Apache Flink, and similar platforms excel at moving data in real-time, they expose technical implementation details, topic names, serialization formats, partition keys, that create barriers for business users. What's missing is a semantic layer: a business-friendly abstraction that translates technical streaming infrastructure into concepts people can understand and trust. 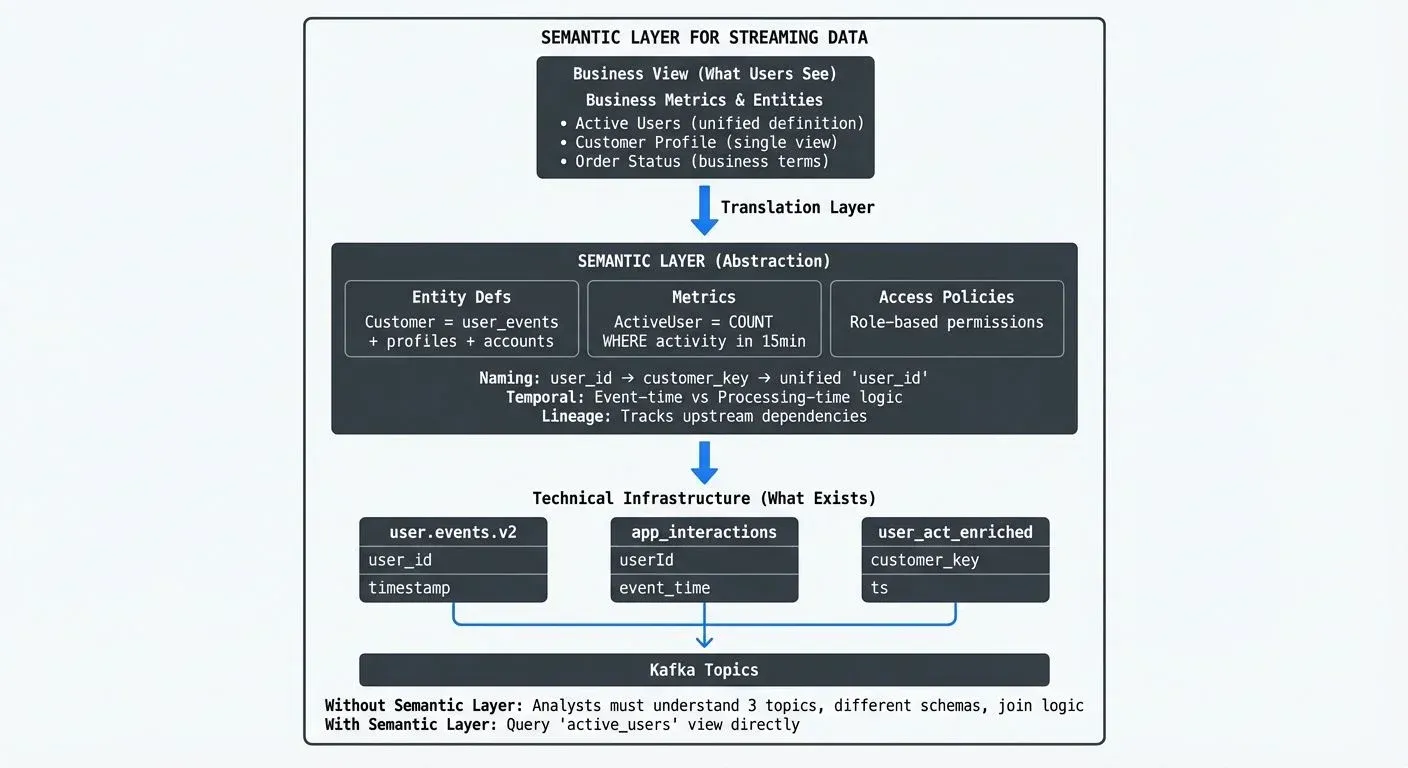
What is a Semantic Layer?
A semantic layer is a business abstraction that sits between raw data systems and data consumers. It provides:
- Consistent business definitions: Instead of
order_status_cd = 3, users queryorder_is_completed = true. - Unified metrics: A single definition of "Monthly Recurring Revenue" that everyone uses, rather than ten different SQL calculations scattered across dashboards.
- Standardized terminology: Common names for entities, attributes, and relationships that remain stable even as underlying schemas change.
- Access policies: Who can see what data, enforced at the semantic level rather than requiring consumers to understand infrastructure permissions.
In traditional data warehousing, semantic layers emerged through tools like Looker's LookML or dbt's MetricFlow (the metrics framework introduced in dbt 1.6+). These systems let teams define business logic once, how to calculate customer lifetime value, what fields constitute personally identifiable information, which dimensions can be grouped together, and reuse those definitions across all analytical queries.
The semantic layer acts as a translation layer. Technical teams maintain the mapping between business concepts and physical tables, columns, and joins. Business teams work entirely with curated metrics and dimensions that make sense in their domain language.
Why Streaming Data Needs Different Treatment
Applying semantic layers to streaming systems introduces challenges that don't exist in batch-oriented warehouses:
- Schema evolution happens continuously: In a data warehouse, schema changes follow controlled release cycles. In streaming systems, producers evolve schemas independently. A semantic layer for streaming must handle situations where the definition of "user_age" changes from an integer to a date-of-birth field across hundreds of upstream producers, all while queries are actively running. For best practices on managing schema changes, see Avro vs Protobuf vs JSON Schema.
- Temporal semantics matter more: Batch queries typically ask "what was the state at end-of-day?" Streaming queries ask "what is happening right now?" or "what happened in the last 15 minutes?" The semantic layer must encode temporal logic: whether a metric represents a point-in-time snapshot, a tumbling window aggregate, or a session-based calculation.
- Event-driven patterns dominate: Warehouse tables contain entities (customers, orders). Streams contain events (user clicked, payment processed). A semantic layer must bridge this gap, helping consumers understand how events relate to entities and how to materialize event streams into queryable state.
- Updates are continuous: In batch systems, metrics get calculated once per day or hour. In streaming, they update continuously. The semantic layer must clarify whether a "revenue" metric is eventually consistent (updates within seconds as events arrive), strongly consistent (guaranteed accurate but potentially slower to compute), or represents a preliminary estimate (fast results that may be refined as late-arriving data is processed).
Consider calculating "active user sessions." In a warehouse, this might be a simple GROUP BY query on a sessions table. In streaming, it requires defining session timeout windows, handling out-of-order events, deciding whether to count partial sessions, and specifying how quickly session counts should reflect reality. All of this complexity should be hidden behind a clean business definition.
Core Components of a Streaming Semantic Layer
Building a semantic layer for streaming data requires several interconnected pieces:
- Business entity definitions: Mapping between technical event schemas and business concepts. For example, defining that a "Customer" entity can be constructed from events in
user_registrations,account_updates, andprofile_changestopics, with specific logic for reconciling conflicting information. - Calculated metrics and aggregations: Pre-defined computations like "orders per minute" or "average session duration" that encode the correct windowing logic, late-arrival handling (logic for events that arrive after their processing window has closed), and aggregation functions. These definitions specify both the calculation logic and the expected latency/accuracy tradeoffs. For more on handling timing challenges, see Handling Late-Arriving Data in Streaming.
- Unified naming conventions: Standard field names across different event types. If five different services publish events with user identifiers, the semantic layer presents a single
user_idfield, handling the mapping fromcustomer_key,userId,user_uuid, etc. - Data lineage and dependencies: Documentation of which upstream topics and schemas feed into each semantic definition. When a producer changes the schema of
payment.processedevents, teams can immediately see which downstream metrics and views are affected. For comprehensive lineage tracking approaches, see Data Lineage: Tracking Data from Source to Consumption. - Access control policies: Role-based rules defining who can consume which semantic views. A customer support team might access real-time order status updates but not the underlying payment processing events that contain sensitive financial data. For detailed coverage of access control strategies, see Access Control for Streaming.
- Temporal context: Clear specification of whether semantic views represent "current state" (like a materialized table), "events in the last hour" (windowed aggregation), or "all historical events" (unbounded stream).
Benefits and Use Cases
Organizations implementing streaming semantic layers report several concrete benefits:
- Cross-team consistency: When the marketing team and finance team both need "new customer" metrics, they use the same definition. The semantic layer enforces that
new_customer_eventsincludes only the first purchase, excludes test accounts, and handles duplicate events identically across all consumers. - Self-service analytics: Business analysts can explore real-time data without writing Kafka Streams jobs or Flink SQL. They work with pre-built views like "active_orders" or "inventory_levels" that handle all the streaming complexity behind the scenes.
- Reduced tribal knowledge: Instead of asking senior engineers "which topic has the authoritative user data?" new team members consult the semantic layer's documentation, which explicitly defines the golden source for each business entity.
- Faster onboarding for data products: In data mesh architectures (an approach where domain teams own and publish their data as products), domain teams publish "data products", curated datasets designed for specific use cases. The semantic layer becomes the interface contract for these products, specifying exactly what business capabilities each stream provides without exposing internal implementation details. For comprehensive coverage of data mesh implementation, see Data Mesh Principles and Implementation.
- Regulatory compliance: When regulations require "deletion of all customer data," the semantic layer identifies every stream and state store that contains customer information, regardless of field names or topic naming conventions.
A real-world example: An e-commerce company built a semantic layer that unified fifty different event streams into five business-oriented views: customer_profile, order_lifecycle, inventory_status, fulfillment_events, and payment_transactions. Teams consuming these views didn't need to know that order_lifecycle actually joined events from warehouse management systems, payment processors, and customer service platforms, or that it handled three different schema versions with different field names.
Implementation Approaches and Tools
Several technical approaches have emerged for building semantic layers over streaming data:
- Extending batch semantic layer tools: Platforms like dbt now support metrics frameworks that can work with streaming sources. Teams define metrics in dbt YAML files, then materialize them through streaming jobs that maintain updated results in a queryable store. This approach works well when streaming data eventually lands in a warehouse or lakehouse that dbt can query. For lakehouse architecture patterns, see Introduction to Lakehouse Architecture.
- Stream-native semantic views: Technologies like ksqlDB (Kafka's SQL interface) or Flink SQL (version 1.18+ with enhanced state management and SQL capabilities) allow defining logical views over streams using SQL DDL. These views act as semantic abstractions, a view called
active_users_by_regionmight encapsulate complex windowing logic, sessionization, and enrichment joins. Consumers query the view without understanding the underlying implementation.
Here's a concrete example using Flink SQL to create a semantic view:
-- Create a semantic view that abstracts complex event processing
CREATE VIEW active_users_by_region AS
SELECT
region,
COUNT(DISTINCT user_id) AS active_users,
TUMBLE_END(event_time, INTERVAL '15' MINUTES) AS window_end
FROM user_events
WHERE event_type IN ('page_view', 'button_click', 'purchase')
AND event_time > CURRENT_TIMESTAMP - INTERVAL '1' HOUR
GROUP BY
region,
TUMBLE(event_time, INTERVAL '15' MINUTES);
-- Business users query the view without knowing the windowing logic
SELECT region, active_users
FROM active_users_by_region
WHERE window_end = (SELECT MAX(window_end) FROM active_users_by_region);This semantic view encodes business logic (what constitutes an "active" user), temporal semantics (15-minute tumbling windows), and data filtering, presenting consumers with a simple, queryable interface. For deeper understanding of windowing concepts, see Windowing in Apache Flink. For comprehensive coverage of Flink's capabilities, see What is Apache Flink.
- Custom catalog and governance layers: Some organizations build metadata catalogs that document semantic meaning separately from physical implementation. These catalogs describe what each stream represents, which fields map to standard business terms, and how to correctly consume the data. Tools like DataHub or Amundsen extended to streaming contexts serve this purpose. For comprehensive data catalog coverage, see What is a Data Catalog.
- Governance platforms for visibility and control: Governance platforms like Conduktor provide infrastructure for managing streaming data governance at scale. Conduktor allows teams to define business-friendly names and descriptions for Kafka topics, enforce access policies based on semantic classifications (PII, financial data, operational metrics), and provide self-service portals where consumers can discover available streams by business capability rather than technical topic names. For advanced use cases like chaos testing and schema governance, Conduktor Gateway extends these capabilities with proxy-level controls using Interceptors. This creates a governance layer that makes semantic meaning visible and actionable across the organization.
- Schema registries with semantic annotations: Extending schema registries (like Confluent Schema Registry or Apicurio Registry) with business metadata, tagging fields with business glossary terms, marking sensitive data, documenting metric calculation rules, turns the schema registry into a lightweight semantic layer.
- Modern streaming infrastructure (2025): With Kafka 4.0's KRaft mode (which became the default in October 2024) eliminating ZooKeeper dependencies, semantic layer implementations benefit from simplified operational models and improved metadata consistency. Real-time OLAP engines like Apache Druid or Apache Pinot serve as high-performance queryable materialization targets for semantic views, enabling sub-second queries on streaming aggregations. Lakehouse table formats (Apache Iceberg, Delta Lake, Apache Hudi) provide ACID guarantees and schema evolution capabilities for streaming semantic views stored in data lakes, bridging the gap between streaming and batch analytical workloads. For detailed coverage of KRaft's operational benefits, see Understanding KRaft Mode in Kafka.
The most effective implementations combine multiple approaches: using Flink SQL to create materialized semantic views, documenting those views in a data catalog, enforcing access through governance platforms like Conduktor, and publishing final metrics to BI tools through dbt-managed tables.
Summary
Semantic layers bridge the gap between streaming infrastructure and business understanding. By providing consistent definitions, unified terminology, and business-friendly abstractions over technical event streams, they enable self-service analytics, reduce knowledge silos, and accelerate data product adoption.
Streaming systems present unique challenges for semantic layers: continuous schema evolution, temporal complexity, event-driven patterns, and real-time updates all require approaches that differ from traditional warehouse-based semantic layers. Successful implementations combine stream-native tools (Flink SQL 1.18+, ksqlDB views), governance platforms like Conduktor for visibility and access control, and metadata catalogs to create cohesive business abstractions.
Modern infrastructure improvements in 2025, particularly Kafka 4.0's KRaft mode, real-time OLAP engines (Druid, Pinot), and lakehouse table formats (Iceberg, Delta Lake, Hudi), simplify semantic layer implementation by providing more robust foundations for metadata management, query performance, and ACID guarantees on streaming data.
As organizations scale their streaming architectures, the semantic layer becomes essential infrastructure, not just for making data understandable, but for maintaining consistency, enforcing governance, and enabling teams to work independently on a shared vocabulary.
Related Concepts
- What is a Data Catalog: Modern Data Discovery - Data catalogs complement semantic layers by providing metadata repositories and business glossaries for streaming data
- Data Lineage: Tracking Data from Source to Consumption - Essential for semantic layers to document which upstream topics feed into business definitions
- Schema Registry and Schema Management - Technical schema management that provides the foundation for semantic layer abstractions
Sources and References
- dbt Semantic Layer: dbt Labs documentation on metrics framework and semantic layer architecture - docs.getdbt.com/docs/build/about-metricflow
- Data Mesh Principles: Zhamak Dehghani's data mesh concepts, particularly data-as-a-product and federated computational governance - martinfowler.com/articles/data-mesh-principles.html
- Apache Kafka Schema Evolution: Confluent documentation on schema compatibility and evolution patterns - docs.confluent.io/platform/current/schema-registry
- Cube.dev Semantic Layer: Architecture for building semantic layers over analytical data sources - cube.dev/docs/product/data-modeling/overview
- Stream Governance Best Practices: Confluent resources on stream lineage, data quality, and governance patterns - confluent.io/resources/ebook/data-governance-in-real-time