Shadow AI: Governing Unauthorized AI in the Enterprise
AI tools have become easy to deploy, but that accessibility has created a governance problem many organizations are only now recognizing: Shadow AI. Like shadow IT before it, Shadow AI is the proliferation of unauthorized, ungoverned AI and machine learning models running in production without proper oversight.
As teams deploy models faster than governance processes can track, organizations face real risks around compliance, security, data governance, and ethical AI. Understanding Shadow AI and building effective governance frameworks is now a practical requirement for any organization scaling AI initiatives. 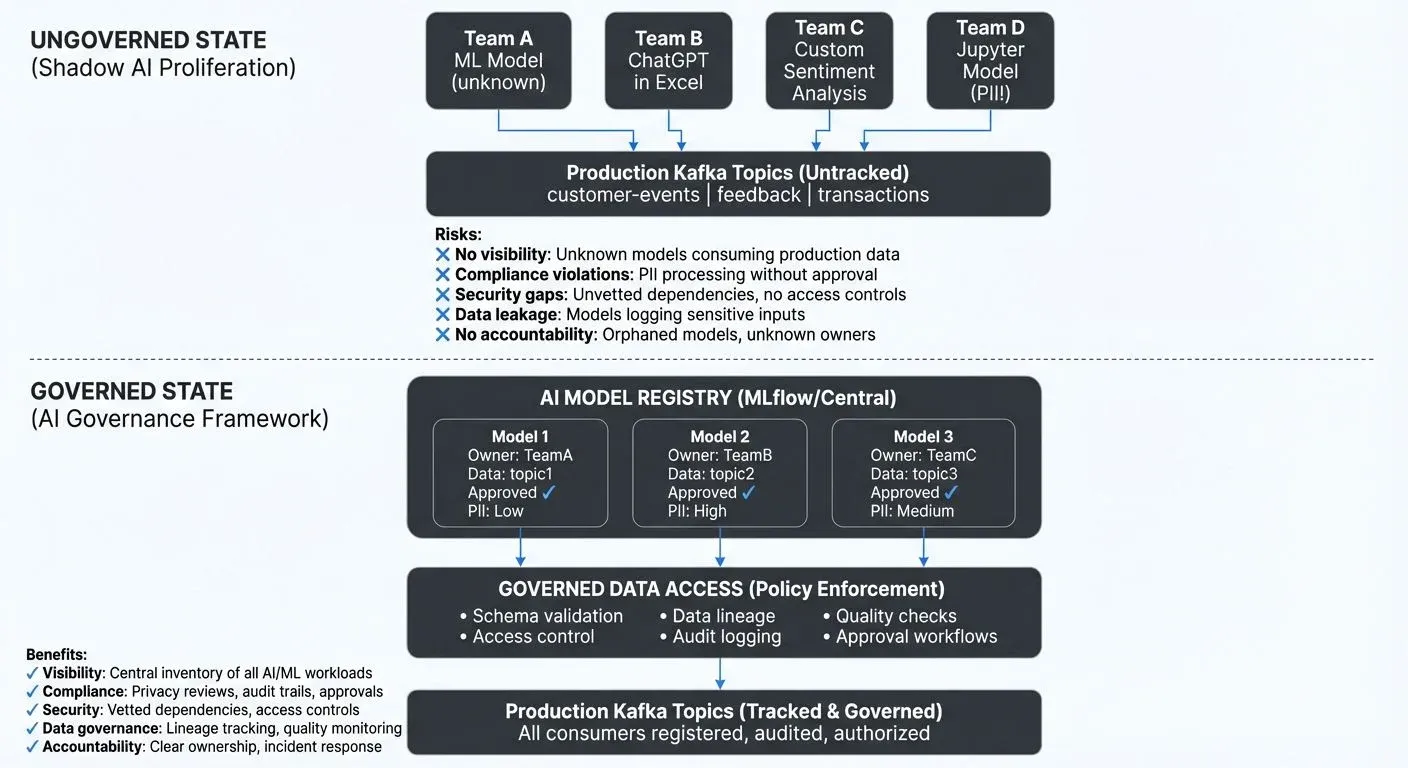
What is Shadow AI?
Shadow AI refers to machine learning models, AI applications, and automated decision-making systems that are deployed and operating in production environments without formal approval, documentation, or oversight from central governance teams. This includes:
- Models trained and deployed by individual teams without registering them in a central inventory
- Third-party AI services integrated into applications without security review
- Experimental models that migrate to production without governance checkpoints
- AI-powered features built using readily available APIs (OpenAI, Anthropic, etc.) without data privacy assessments
- Consumer AI tools used for business-critical workflows (ChatGPT for code generation, data analysis, content creation)
Real-World Example: A marketing analyst creates a sentiment analysis model that consumes the company's customer feedback stream from Kafka. What starts as a personal experiment for a quarterly report quietly transitions into an automated daily dashboard that the CMO presents to the board. The model was never registered, never security-reviewed, and processes customer PII without privacy assessment, yet it's now influencing executive decisions. This is Shadow AI: not malicious, but ungoverned and potentially risky.
The defining characteristic of Shadow AI is not malicious intent — it's the absence of visibility, documentation, and governance oversight.
Why Shadow AI Emerges
Shadow AI doesn't arise from negligence alone. Several organizational and technical factors create the conditions for ungoverned AI to flourish:
- Ease of Deployment: Modern AI platforms have dramatically lowered the barriers to model deployment. A data scientist can train a model on their laptop, containerize it, and deploy it to production infrastructure in hours. The friction that once naturally created governance checkpoints has largely disappeared.
- Pressure to Ship: Product teams face intense pressure to deliver AI-powered features quickly. When formal governance processes are perceived as slow or bureaucratic, teams find workarounds. A model that starts as an experiment can quietly transition to serving production traffic without ever entering the approval pipeline.
- Decentralized AI Adoption: Unlike traditional IT infrastructure that required centralized procurement and deployment, AI tools are distributed across the organization. Marketing teams deploy sentiment analysis models, sales teams integrate AI prospecting tools, and customer support implements chatbots, all potentially without central IT involvement.
- Lack of Clear Process: Many organizations lack well-defined governance frameworks for AI. When teams don't know how to get AI initiatives approved, or when no clear process exists, they proceed independently rather than waiting for clarity.
The Risks of Ungoverned AI
Shadow AI introduces multiple categories of risk that can have serious business and regulatory consequences:
- Compliance Violations: Unregistered AI models may process personal data in ways that violate GDPR, CCPA, or industry-specific regulations. Without governance oversight, organizations lose the ability to demonstrate compliance with AI transparency and explainability requirements that regulators increasingly demand.
- Security Vulnerabilities: Ungoverned models bypass security reviews that would identify vulnerabilities like model poisoning, adversarial attacks, or insecure data handling. AI models trained on sensitive data without proper access controls can become vectors for data exfiltration.
- Data Leakage: Shadow AI often consumes data streams and datasets without proper classification or access controls. A model might inadvertently expose customer PII, financial data, or intellectual property through its predictions or by logging sensitive inputs.
- Bias and Fairness Issues: Models deployed without ethical AI review may perpetuate or amplify biases in training data, leading to discriminatory outcomes in hiring, lending, healthcare, or other high-stakes decisions. Without governance, there's no systematic assessment of fairness metrics or bias testing. For data quality frameworks that can help prevent biased training data, see Building a Data Quality Framework.
- Operational Fragility: Untracked models create hidden dependencies in production systems. When these models fail or degrade, incident response teams lack the documentation needed for effective troubleshooting. Organizations can't assess the blast radius of data pipeline changes when they don't know what models depend on specific data sources.
Shadow AI in Streaming Environments
Real-time data streaming architectures present unique challenges for Shadow AI detection and governance. The distributed nature of streaming platforms like Apache Kafka creates multiple opportunities for ungoverned AI to emerge:
- Silent Stream Consumers: A data scientist might attach a consumer to a production Kafka topic to extract features for model training, then transition that same consumer to serve real-time predictions, all without formal registration. The streaming platform sees just another consumer application. Understanding consumer behavior is critical, see Consumer Lag Monitoring for tracking patterns that might indicate Shadow AI workloads.
- Model Proliferation: In event-driven architectures, models can be deployed as lightweight microservices that consume events, make predictions, and produce results to output topics. These can multiply rapidly across namespaces and clusters without centralized visibility. For foundational understanding of event-driven patterns, see Event-Driven Architecture.
- Data Access Sprawl: Streaming platforms excel at making data broadly accessible, but this same characteristic enables Shadow AI. A model deployed in one business unit can easily consume data streams owned by another unit, potentially violating data access policies.
- API-Driven Integration: Modern streaming platforms expose APIs that make it trivial to create topics, configure consumers, and set up data pipelines. This programmatic access, while powerful, allows ungoverned models to self-provision the infrastructure they need.
Detecting Shadow AI
Discovering ungoverned AI in distributed environments requires a multi-layered approach. For comprehensive coverage of AI discovery techniques and tooling, see AI Discovery and Monitoring.
- Network and API Monitoring: Track unusual patterns in API calls to AI platforms (OpenAI, AWS SageMaker, Azure ML). Monitor network traffic for connections to external AI services. Analyze authentication logs to identify which teams or individuals are deploying AI workloads.
- Data Access Audits: Systematically review who is consuming your data streams and datasets. In Kafka environments, audit consumer groups (logical groupings of consumers that read from topics) and their subscriptions. Identify consumers without registered business purposes. For detailed coverage of streaming audit capabilities, see Audit Logging for Streaming Platforms.
Tools like Conduktor Gateway, a Kafka proxy, provide visibility into topic access patterns and help enforce data governance policies across your streaming infrastructure, including the ability to intercept, validate, and block unauthorized access to sensitive data streams using Interceptors. For comprehensive access control strategies, refer to Access Control for Streaming.
- Infrastructure Inventory: Scan container registries, Kubernetes namespaces, and serverless function deployments for ML frameworks and model artifacts. Look for inference endpoints (HTTP/gRPC services that serve model predictions), model servers (TensorFlow Serving, TorchServe, MLflow Model Server), and AI-related dependencies in deployed applications.
- Code Repository Analysis: Search codebases for imports of ML libraries, calls to AI APIs, and references to model artifacts. This can reveal AI usage before it reaches production.
- Self-Reporting and Cultural Initiatives: Create lightweight processes that make it easy for teams to register AI projects. Amnesty programs allow teams to retroactively document Shadow AI without penalty.
Practical Example: Detecting Shadow AI in Kafka
Here's how to programmatically audit Kafka consumer groups to identify potential ungoverned AI models consuming your data streams:
from kafka.admin import KafkaAdminClient, ConfigResource, ConfigResourceType
from kafka import KafkaConsumer
import re
# Connect to Kafka cluster
admin_client = KafkaAdminClient(
bootstrap_servers=['localhost:9092'],
client_id='shadow-ai-detector'
)
# Get all consumer groups
consumer_groups = admin_client.list_consumer_groups()
# Patterns that suggest ML/AI workloads
ml_patterns = [
r'ml[-_]',
r'model[-_]',
r'inference[-_]',
r'predict[-_]',
r'feature[-_]',
r'training[-_]'
]
suspicious_consumers = []
for group_id, group_type in consumer_groups:
# Check if consumer group name matches ML patterns
is_ml_related = any(re.search(pattern, group_id, re.IGNORECASE)
for pattern in ml_patterns)
if is_ml_related:
# Get consumer group details
group_desc = admin_client.describe_consumer_groups([group_id])
# Cross-reference with your model registry
if not is_registered_in_model_registry(group_id):
suspicious_consumers.append({
'consumer_group': group_id,
'members': len(group_desc[0].members),
'state': group_desc[0].state
})
# Report findings
print(f"Found {len(suspicious_consumers)} potentially ungoverned AI consumers:")
for consumer in suspicious_consumers:
print(f" - {consumer['consumer_group']} ({consumer['members']} members, {consumer['state']})")This detection script can be run periodically and integrated with alerting systems to identify Shadow AI as it emerges.
Building AI Governance Frameworks
Effective AI governance balances oversight with enablement. The goal isn't to prevent AI adoption but to ensure it happens responsibly:
AI Model Registry: Establish a central inventory of all AI/ML models in production or development. Capture essential metadata: purpose, owner, data sources, performance metrics, deployment status, and approval history. This registry becomes the foundation for all governance activities.
Modern platforms like MLflow (version 2.0+, released 2024) provide comprehensive model registry capabilities with versioning, lineage tracking, and lifecycle management. Here's an example of registering a model with proper governance metadata:
import mlflow
from mlflow.tracking import MlflowClient
# Set tracking URI for centralized registry
mlflow.set_tracking_uri("https://mlflow.company.com")
# Register model with governance metadata
with mlflow.start_run():
# Train your model
model = train_model(training_data)
# Log model with comprehensive governance metadata
mlflow.sklearn.log_model(
model,
artifact_path="model",
registered_model_name="customer-churn-predictor"
)
# Add governance tags
mlflow.set_tags({
"owner": "data-science-team@company.com",
"business_unit": "customer-success",
"data_sources": "kafka://prod-cluster/customer-events,s3://data-lake/customer-profiles",
"pii_exposure": "high",
"approval_status": "pending",
"approvers": "data-governance@company.com,legal@company.com",
"deployment_env": "production"
})
# Log metrics for monitoring
mlflow.log_metrics({
"accuracy": 0.94,
"f1_score": 0.91,
"training_samples": 1000000
})For organizations building real-time AI on streaming data, integrate your model registry with data lineage tracking to automatically capture which Kafka topics and data streams each model consumes. Additionally, consider implementing a centralized feature store to manage and govern feature pipelines, see Feature Stores for Machine Learning for detailed implementation patterns.
Approval Workflows: Design tiered approval processes based on model risk. Low-risk experiments might require minimal oversight, while models making high-stakes decisions need comprehensive review including security, legal, ethics, and data governance assessments.
Implement policy-as-code using tools like Open Policy Agent (OPA) to automatically enforce governance rules. For example, you can create policies that automatically block model deployments consuming PII data without appropriate approvals:
# Example OPA policy for AI model deployment
package ai_governance
# Deny deployment if model consumes PII without privacy review
deny[msg] {
input.model.data_classification == "pii"
not input.model.approvals.privacy_review
msg := "Models consuming PII require privacy team approval before deployment"
}
# Require higher approvals for high-risk models
deny[msg] {
input.model.risk_level == "high"
count(input.model.approvals.approvers) < 3
msg := "High-risk models require at least 3 approvals from governance stakeholders"
}Data Lineage Tracking: Integrate AI governance with your existing data governance framework. Every model should document its data dependencies, which streams, tables, and APIs it consumes. This enables impact analysis when upstream data changes and helps enforce data access policies.
Adopt OpenLineage, the Linux Foundation standard for data lineage (widely adopted by 2025), to automatically track data flows from source systems through transformation pipelines to AI models. For comprehensive coverage of lineage capabilities, see Data Lineage Tracking. OpenLineage integrations exist for Kafka, Spark, Airflow, and most major data platforms, enabling automated discovery of data dependencies without manual documentation.
- Ethical AI Review: Establish criteria and processes for assessing fairness, bias, and ethical implications. This might include testing for disparate impact, evaluating explainability requirements, and ensuring human oversight for automated decisions.
- Continuous Monitoring: AI governance doesn't end at deployment. Monitor models for drift, degraded performance, changing data distributions, and compliance with SLAs. Track actual usage patterns to identify models that have grown beyond their original scope.
Implement AI observability using OpenTelemetry (the CNCF standard for observability) to instrument your ML models with tracing, metrics, and logs. This enables you to track model performance, detect anomalies, and maintain governance compliance in production. For streaming AI workloads, integrate with distributed tracing to understand the full request path from data ingestion through model inference to downstream consumers, see Distributed Tracing for Kafka Applications for implementation patterns.
Extend your data observability practices to cover AI models, see What is Data Observability: The Five Pillars for foundational concepts that apply equally to monitoring AI models and the data pipelines that feed them.
Balancing Innovation and Governance
The tension between velocity and control is real. Organizations that make governance too heavy create the exact conditions that drive Shadow AI. The most effective approaches share several characteristics:
- Make Governance Easy: Invest in tooling and automation that reduces the friction of compliance. Self-service portals for registering models, automated data lineage collection, and integrated approval workflows embedded in CI/CD pipelines make doing the right thing the path of least resistance.
- Education Over Enforcement: Help teams understand why governance matters. When data scientists and engineers understand the risks of ungoverned AI, to the business, to customers, and to their own careers, they become advocates rather than resisters.
- Federated Responsibility: Central governance teams can't review every model in large organizations. Instead, establish clear standards and empower domain teams to make governance decisions within guardrails. Create domain-specific AI leads who bridge central governance and team execution.
- Enable Experimentation: Distinguish clearly between experimental models (running on non-production data, not making business decisions) and production AI. Create sandbox environments with relaxed governance where teams can innovate freely, with clear criteria that trigger governance review before production deployment.
Integration with Data Governance
AI governance cannot exist in isolation from broader data governance initiatives. Every AI model is fundamentally a data consumer, and effective governance requires tight integration:
- Models should inherit data classification and access controls from their source datasets, see Data Classification and Tagging Strategies for implementation approaches
- Data quality issues flagged in governance systems should trigger model retraining reviews, for automated quality checks, refer to Automated Data Quality Testing
- Data retention policies must account for model training data and inference logs
- Privacy impact assessments should automatically flag when models consume PII, for implementation patterns, see Data Masking and Anonymization for Streaming
For streaming architectures, unified governance platforms like Conduktor provide oversight across data flows and the AI models that depend on them, enabling organizations to enforce consistent policies from data production through model consumption. Understanding your overall governance framework is essential, see Data Governance Framework: Roles and Responsibilities for establishing organizational structures that support AI governance.
Modern AI Governance Tools (2025)
The AI governance tooling landscape has matured significantly by 2025. Organizations building comprehensive governance frameworks typically integrate several specialized tools:
Model Registry and Tracking:
- MLflow (open-source) - Model versioning, experiment tracking, and registry
- Weights & Biases - Experiment tracking with collaborative features
- Cloud-native registries: AWS SageMaker Model Registry, Azure ML Model Registry, Google Vertex AI Model Registry
Data Lineage and Cataloging:
- OpenLineage - Open standard for data lineage (Linux Foundation)
- DataHub - Open-source data catalog with lineage (LinkedIn/Linux Foundation)
- Apache Atlas - Metadata management and data governance
Policy Enforcement:
- Open Policy Agent (OPA) - Policy-as-code engine (CNCF)
- Styra - Enterprise OPA management
- Kubernetes admission controllers for deployment-time governance
Observability and Monitoring:
- OpenTelemetry - Distributed tracing and metrics (CNCF standard)
- Prometheus + Grafana - Metrics and dashboards
- Specialized ML monitoring: Arize AI, Aporia, Fiddler AI
Streaming Governance:
- Conduktor Gateway - Kafka governance, data quality, and access control
- Schema Registry - Schema evolution and compatibility (see Schema Registry and Schema Management)
Data Quality:
- Great Expectations - Data validation framework (see Great Expectations Data Testing Framework)
- Soda Core - Data quality testing
- dbt tests - Transformation testing (see dbt Tests and Data Quality Checks)
The key to effective governance is integrating these tools into a cohesive framework where model metadata flows automatically from registry to lineage system, policies are enforced at deployment time, and observability spans the entire ML lifecycle.
Building Your AI Inventory
The first step in addressing Shadow AI is understanding what AI you have. Start building your inventory:
- Discovery Phase: Use the detection methods above to find existing models
- Documentation: For each model, capture owner, purpose, data sources, deployment details, and business impact
- Risk Assessment: Categorize models by risk level based on the decisions they make and the data they use
- Prioritization: Address high-risk Shadow AI first while creating pathways for lower-risk models to come into compliance
- Process Establishment: Based on what you learned, design approval and registration processes that teams will actually use
The Path Forward
Shadow AI is a natural consequence of AI democratization and rapid innovation. The answer is not to slow down AI adoption but to build governance frameworks that scale with it. Organizations that succeed make governance part of the tools, workflows, and culture rather than an external burden imposed after the fact.
As AI systems make increasingly consequential decisions and regulators demand greater transparency and accountability, ungoverned AI represents a real business risk. Organizations with mature AI governance can move faster with confidence, because their AI landscape is mapped, monitored, and managed.
The question is not whether to govern AI — regulatory and business pressures make that inevitable. The question is whether you govern it proactively, building systems that discover and manage AI before problems emerge, or reactively, after a compliance violation, security breach, or algorithmic bias incident forces the issue.
Related Concepts
- Data Governance Framework: Roles and Responsibilities - Framework for governing AI and data assets
- Real-Time Analytics with Streaming Data - Monitor AI usage and performance
- Kafka Connect: Building Data Integration Pipelines - Integrate AI governance with data pipelines
Sources and References
- NIST AI Risk Management Framework - Federal framework for managing AI risks and governance
- EU AI Act - Comprehensive regulatory framework for AI systems
- MLOps Community: Model Governance - Best practices for ML model management and governance
- GDPR and AI: Transparency Requirements - Data protection requirements for AI systems
- ISO/IEC 42001: AI Management System - International standard for AI management systems