Cross-Organization Data Sharing Patterns
Organizations increasingly need to share data beyond their boundaries. Supply chain partners exchange inventory updates, financial institutions collaborate on fraud detection, and healthcare networks share patient records across hospital systems. Each scenario requires careful consideration of technical architecture, security, and governance.
This article explores common patterns for cross-organization data sharing, the role of data streaming platforms, and practical considerations for implementation.
Common Data Sharing Patterns
Organizations use several architectural patterns to share data, each with distinct characteristics and trade-offs. 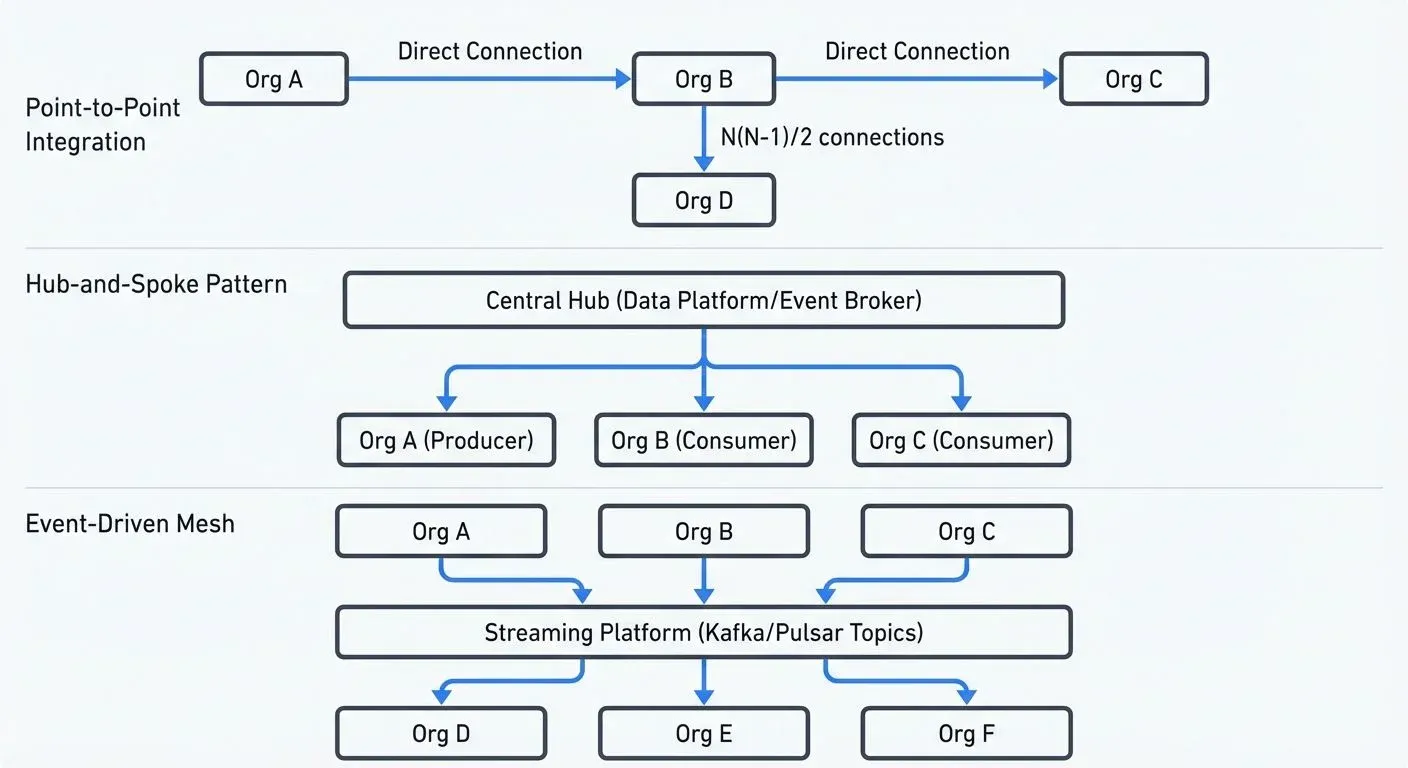
Point-to-Point Integration
The simplest approach connects two organizations through direct integration. One system sends data via APIs, file transfers, or database connections to another system. This pattern works well for limited partnerships but becomes difficult to manage as the number of connections grows. With N organizations, you potentially need N(N-1)/2 connections.
Point-to-point integration often uses REST APIs, SFTP, or direct database access. While straightforward to implement initially, this pattern creates tight coupling and makes it hard to add new partners or change data formats.
Hub-and-Spoke
A hub-and-spoke pattern centralizes data sharing through an intermediary platform. Organizations connect to the hub, which handles routing, transformation, and delivery. This reduces the number of connections from N² to N and provides a single place to enforce policies and monitor data flows.
Cloud data platforms, API gateways, and data marketplaces often implement hub-and-spoke patterns. The hub manages authentication, rate limiting, and data format conversions, simplifying integration for participating organizations.
Mesh and Event-Driven Patterns
Modern architectures increasingly use event-driven patterns where organizations publish events to shared event streams. Other organizations subscribe to relevant events and process them independently. This creates a loosely coupled mesh where producers and consumers don't need direct knowledge of each other.
For foundational event-driven concepts, see Event-Driven Architecture and Event Stream Fundamentals.
Event-driven patterns work particularly well for real-time data sharing and scenarios where multiple organizations need the same data. A manufacturer might publish inventory events that flow to distributors, logistics providers, and retailers simultaneously.
Security and Access Control Models
Cross-organization data sharing requires robust security at multiple levels.
Authentication and Authorization
Organizations must verify the identity of data consumers (authentication) and control what data they can access (authorization). Common approaches include:
- OAuth 2.0 and OIDC for API-based sharing, allowing organizations to grant limited access without sharing credentials. In 2025, Workload Identity Federation enables cross-cloud authentication without managing service account keys.
- Mutual TLS (mTLS) for service-to-service communication, ensuring both parties authenticate each other with certificate-based verification
- API keys and tokens for simpler scenarios, though these require careful rotation and management
- SASL/SCRAM or SASL/OAUTHBEARER for Kafka authentication, with OAuth providing better support for token-based, time-limited access
For Kafka-specific authentication, see Kafka Authentication: SASL, SSL, OAuth and mTLS for Kafka.
Example OAuth 2.0 client credentials flow for cross-organization API access:
import requests
from requests.auth import HTTPBasicAuth
# Partner organization obtains access token
token_response = requests.post(
'https://auth.primary-org.com/oauth/token',
auth=HTTPBasicAuth(client_id, client_secret),
data={
'grant_type': 'client_credentials',
'scope': 'data:read:inventory'
}
)
access_token = token_response.json()['access_token']
# Use token to access shared data API
data_response = requests.get(
'https://api.primary-org.com/v1/inventory',
headers={'Authorization': f'Bearer {access_token}'}
)
inventory_data = data_response.json()Authorization typically uses role-based access control (RBAC) or attribute-based access control (ABAC). RBAC grants permissions based on predefined roles (e.g., "partner-org-reader"), while ABAC makes access decisions based on dynamic attributes like user department, data classification, time of day, or request context. For example, a healthcare network might grant a partner hospital read access to specific patient records based on attributes like patient consent, treating physician, and active care relationship.
For comprehensive access control patterns, see Data Access Control: RBAC and ABAC.
Example ABAC policy for cross-organization data access:
{
"effect": "allow",
"principal": "organization:partner-hospital-123",
"action": "kafka:consume",
"resource": "topic:patient-records",
"conditions": {
"patientConsent": "granted",
"careRelationship": "active",
"dataClassification": "phi-shared",
"accessTime": "business-hours"
}
}Data Masking and Encryption
Sensitive data often requires masking or encryption before sharing. Organizations might:
- Encrypt data in transit using TLS 1.3+ and at rest using encryption keys managed by each organization
- Apply field-level masking to hide sensitive attributes like social security numbers or account details
- Use tokenization to replace sensitive values with non-sensitive tokens that can be mapped back only by authorized systems
- Apply dynamic data masking based on the consumer's identity and permissions
For streaming data encryption, see Encryption at Rest and in Transit for Kafka and Data Masking and Anonymization for Streaming.
Example data masking before cross-organization sharing:
import hashlib
import json
def mask_sensitive_fields(transaction, consumer_org):
"""Mask data based on consuming organization's permissions."""
masked = transaction.copy()
# Always mask full account numbers for external orgs
if consumer_org != 'internal':
masked['account_number'] = f"****{transaction['account_number'][-4:]}"
masked['customer_name'] = "REDACTED"
# Replace SSN with one-way hash for fraud detection
if 'ssn' in transaction:
masked['ssn_hash'] = hashlib.sha256(
transaction['ssn'].encode()
).hexdigest()
del masked['ssn']
# Preserve transaction patterns and amounts for analysis
# (amount, timestamp, merchant_category remain)
return masked
# Original transaction
transaction = {
"transaction_id": "tx_12345",
"account_number": "1234567890",
"customer_name": "John Doe",
"ssn": "123-45-6789",
"amount": 245.50,
"merchant_category": "retail",
"timestamp": "2025-01-15T10:30:00Z"
}
# Masked version for partner fraud detection system
shared_transaction = mask_sensitive_fields(transaction, consumer_org='partner-bank')A financial institution sharing transaction data for fraud analysis might mask customer names and account numbers while preserving transaction patterns and amounts, allowing partners to detect fraud without exposing PII.
For PII handling strategies, see PII Detection and Handling in Event Streams.
Data Streaming in Cross-Organization Scenarios
Event streaming platforms like Apache Kafka have become popular for cross-organization data sharing because they support real-time data flows, decouple producers from consumers, and provide built-in durability and replay capabilities.
Modern streaming platforms (Kafka 4.0+, Apache Pulsar) have evolved significantly in 2025, offering native multi-tenancy, improved security models, and built-in data sharing capabilities that simplify cross-organization integration.
Kafka for Multi-Organization Data Sharing
Organizations can use Kafka in several ways for cross-organization sharing:
Multi-Cluster Replication: Each organization runs its own Kafka cluster. MirrorMaker 2 or Confluent Cluster Linking replicates selected topics between clusters, maintaining data sovereignty while enabling sharing. With Kafka 4.0+, KRaft mode (replacing ZooKeeper) simplifies cluster management and improves replication performance. This pattern works well when organizations want complete control over their infrastructure.
For detailed cluster replication setup, see Kafka MirrorMaker 2 for Cross-Cluster Replication.
Shared Cluster with Multi-Tenancy: Organizations share a Kafka cluster but use ACLs and quotas to isolate data and enforce access policies. Kafka 4.0+ provides enhanced multi-tenancy features including improved quota management and namespace isolation. This reduces operational overhead but requires careful security configuration.
For comprehensive ACL configuration, see Kafka ACLs and Authorization Patterns and Multi-Tenancy in Kafka Environments.
Event Streaming as Integration Layer: Kafka acts as the hub in a hub-and-spoke pattern. Organizations publish events to central topics, and consumers subscribe based on their needs. Schema Registry (Confluent Schema Registry, AWS Glue Schema Registry, or Apicurio Registry) ensures data compatibility across organizations.
For schema management best practices, see Schema Registry and Schema Management.
Real-World Example: Supply Chain Data Sharing
Consider a manufacturer sharing real-time inventory data with distributors. The manufacturer publishes inventory events to a Kafka topic. Each distributor subscribes to events for products they carry. When inventory drops below a threshold, distributors automatically adjust orders.
This event-driven approach means the manufacturer doesn't need to know which distributors exist or how they use the data. New distributors can join by subscribing to the topic without requiring changes to the manufacturer's systems.
Stream governance platforms help manage this complexity by providing topic-level access control, schema validation, and data masking capabilities to configure organizational access, apply transformations, and monitor data flows across boundaries.
Modern Data Sharing Platforms (2025)
Several specialized platforms have emerged to simplify cross-organization data sharing:
- Conduktor Partner Zones: Enables organizations to share Kafka topics across cloud accounts and regions with fine-grained access control (see Conduktor Partner Zones for secure cross-organization data sharing). Producers maintain ownership while granting read access to external consumers through governance policies. This approach eliminates data duplication and reduces operational complexity.
- Delta Sharing: An open protocol for secure data sharing that works with data lake tables (Delta Lake, Apache Iceberg, Apache Hudi). Organizations share live data without copying it, using a simple REST API for access control. Recipients can query shared data using their preferred tools (Spark, pandas, Power BI) without requiring direct cloud storage access.
For implementation details, see Zero-Copy Data Sharing.
- Apache Iceberg REST Catalog: Provides unified metadata access across organizations. Teams can share table metadata and enforce fine-grained access controls at the table and column level while maintaining separate storage accounts.
- Managed API Gateways: Cloud platforms (AWS API Gateway, Google Cloud Apigee, Azure API Management) offer built-in authentication, rate limiting, and monitoring for API-based data sharing. GraphQL Federation enables organizations to expose unified APIs while maintaining separate backend services.
For API gateway patterns, see API Gateway Patterns for Data Platforms.
Governance and Compliance Considerations
Cross-organization data sharing requires clear governance frameworks to manage responsibilities, quality, and compliance.
For broader governance frameworks, see Data Governance Framework: Roles and Responsibilities and Data Mesh Principles and Implementation.
Data Contracts and SLAs
Organizations should establish formal agreements defining:
- Data contracts that specify schemas, update frequencies, and data quality expectations
- Service level agreements (SLAs) covering availability, latency, and support
- Change management processes for schema evolution and breaking changes
For implementing data contracts, see Data Contracts for Reliable Pipelines.
For SLA monitoring and management, see Data Freshness Monitoring & SLA Management and SLA for Streaming.
These contracts prevent misunderstandings and provide a foundation for resolving issues when they arise.
Regulatory Compliance
Data sharing across organizations often involves regulatory requirements:
- GDPR requires explicit consent for personal data sharing and mandates data minimization
- HIPAA governs healthcare data sharing and requires business associate agreements
- Financial regulations like PCI DSS control how payment card data can be shared
For detailed GDPR compliance guidance, see GDPR Compliance for Data Teams.
Organizations must map data flows to understand which regulations apply and implement appropriate controls. Audit logs tracking who accessed what data when are essential for compliance and incident response.
For audit logging implementation, see Audit Logging for Streaming Platforms and Streaming Audit Logs.
Implementation Challenges and Best Practices
Several practical challenges arise when implementing cross-organization data sharing.
Network Connectivity
Organizations often operate behind firewalls with restricted network access. Options include:
- API gateways that provide controlled access through public endpoints
- VPN tunnels for private connectivity between networks
- Cloud-based integration platforms that both organizations can reach without direct network connections
Event streaming platforms can simplify network challenges. Organizations connect outbound to a shared Kafka cluster, avoiding the need for inbound firewall rules.
Schema Evolution
Data formats evolve over time, creating compatibility challenges. Best practices include:
- Use schema registries to version and validate schemas
- Apply backward and forward compatibility rules so changes don't break consumers
- Provide advance notice of breaking changes and support multiple schema versions during transitions
For comprehensive schema evolution strategies, see Schema Evolution Best Practices and Schema Evolution in Apache Iceberg.
Schema management tools help teams validate schema changes before deployment and understand which consumers might be affected by changes.
Monitoring and Observability
Understanding data flows across organizations requires monitoring at multiple levels:
- Infrastructure metrics tracking throughput, latency, and errors (using Prometheus, Grafana, DataDog, or cloud-native monitoring)
- Business metrics measuring data freshness, completeness, and quality
- Security metrics detecting unusual access patterns or potential breaches using anomaly detection
- Distributed tracing with OpenTelemetry to track data flows across organizational boundaries
Modern observability platforms in 2025 provide:
- OpenTelemetry integration: Standardized instrumentation for Kafka producers, consumers, and stream processors, enabling end-to-end trace correlation across organizations
- Real-time alerting: Automated notifications when SLAs are violated or anomalies detected
- Cross-organization dashboards: Unified views showing data flow health across all participating organizations
For Kafka-specific monitoring, see Kafka Cluster Monitoring and Metrics and Distributed Tracing for Kafka Applications.
Example OpenTelemetry instrumentation for cross-organization Kafka producer:
from opentelemetry import trace
from opentelemetry.instrumentation.kafka import KafkaInstrumentor
from kafka import KafkaProducer
# Initialize OpenTelemetry tracing
tracer = trace.get_tracer(__name__)
KafkaInstrumentor().instrument()
# Create instrumented Kafka producer
producer = KafkaProducer(
bootstrap_servers='kafka.primary-org.com:9092',
security_protocol='SASL_SSL',
sasl_mechanism='OAUTHBEARER'
)
# Traces automatically include organization context
with tracer.start_as_current_span("share_inventory_data") as span:
span.set_attribute("organization", "manufacturer-123")
span.set_attribute("partner_count", 5)
producer.send(
'inventory-updates',
key=b'product-sku-456',
value=inventory_event_json
)
producer.flush()Centralized monitoring platforms that aggregate metrics from all participants help teams quickly identify and resolve issues. In 2025, organizations increasingly use federated observability where each org maintains control over their telemetry data while sharing aggregated health metrics.
Summary
Cross-organization data sharing enables collaboration while introducing complexity in architecture, security, and governance. The most appropriate pattern depends on the number of partners, real-time requirements, and control needs.
Point-to-point integration works for simple scenarios but doesn't scale. Hub-and-spoke patterns centralize management at the cost of creating a single point of control. Event-driven architectures using platforms like Kafka 4.0+ provide loose coupling and real-time capabilities while requiring careful attention to security and schema management.
In 2025, modern data sharing platforms have significantly simplified cross-organization integration:
- Stream sharing technologies (Conduktor) eliminate data replication with governance policies
- Zero-copy protocols (Delta Sharing, Iceberg REST catalog) enable secure data access without duplication
- Enhanced multi-tenancy in Kafka 4.0+ with KRaft improves isolation and performance
- OpenTelemetry integration provides standardized observability across organizational boundaries
- Workload Identity Federation simplifies cross-cloud authentication
Successful implementations establish clear data contracts, implement layered security (authentication, authorization, and encryption), and maintain monitoring with distributed tracing. Modern platforms with built-in schema management, access control, and data masking reduce the operational burden of managing these data flows.
For quality assurance in shared data, see Building a Data Quality Framework and Data Quality Dimensions: Accuracy, Completeness, and Consistency.
As organizations participate in more data ecosystems, these patterns and practices become necessary for reliable, secure, and scalable data sharing.
Related Concepts
- Kafka ACLs and Authorization Patterns - Fine-grained access control essential for securing cross-organization data streams
- Kafka Authentication: SASL, SSL, OAuth - Authentication mechanisms for verifying identity across organizational boundaries
- Encryption at Rest and in Transit for Kafka - Protecting sensitive data as it moves between organizations
Sources and References
- Apache Kafka Documentation: "Multi-Tenancy and Data Isolation" - https://kafka.apache.org/documentation/#multitenancy
- Conduktor Platform Documentation - https://www.conduktor.io/
- Apache Kafka 4.0 Documentation: "KRaft Mode and Security" - https://kafka.apache.org/documentation/#kraft
- Delta Sharing Protocol Specification (2024) - https://github.com/delta-io/delta-sharing
- OpenTelemetry Kafka Instrumentation (2025) - https://opentelemetry.io/docs/instrumentation/kafka/
- Martin Kleppmann: "Designing Data-Intensive Applications" - Chapter 11 on Stream Processing and Data Integration
- AWS Whitepaper: "Securely Share Data Across AWS Accounts" - https://docs.aws.amazon.com/whitepapers/latest/architecting-hipaa-security-and-compliance-on-aws/data-sharing.html
- GDPR Official Text: Articles on Data Processing and Third-Party Sharing - https://gdpr-info.eu/
Written by Stéphane Derosiaux · Last updated May 12, 2026