Event Streams: The Foundation of Real-Time Architectures
Event streams are at the core of modern real-time data architectures. Every click on a website, every transaction in a payment system, every sensor reading from an IoT device — these are events flowing through distributed systems. Understanding event streams is essential for building scalable, real-time applications that react to changes as they happen. 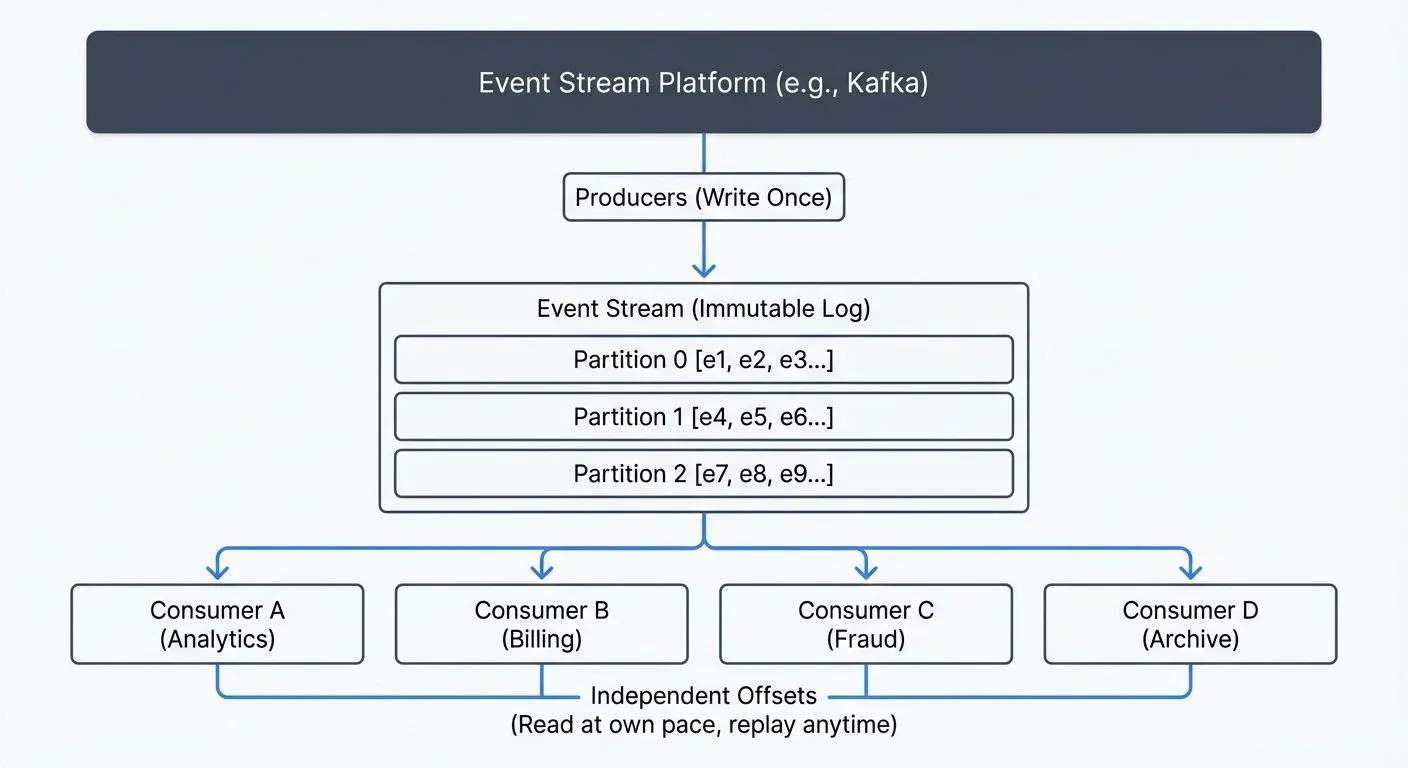
What is an Event Stream?
An event stream is a continuous, ordered sequence of events produced by operational systems. Unlike traditional databases that store the current state, event streams capture what happened over time as an immutable log of facts.
To understand event streams, it helps to contrast them with other data systems:
- Event Stream vs Database: A database stores the current state of your system. If a user updates their email address, the old value is typically overwritten. An event stream, however, records both events: "EmailChanged from old@example.com" and "EmailChanged to new@example.com". You can reconstruct state at any point in time by replaying events.
- Event Stream vs Message Queue: Message queues are designed for task distribution and typically delete messages once consumed. Event streams are designed for data distribution and retain events for a configurable period (hours, days, or indefinitely). Multiple consumers can independently read the same events without affecting each other.
The key insight is that event streams treat data as a first-class, replayable asset rather than ephemeral messages or mutable records.
Anatomy of an Event
Each event in a stream consists of several components that provide structure and context:
- Key: An optional identifier that determines how events are partitioned and ordered. Events with the same key are guaranteed to be ordered and stored in the same partition. For example, all events for "user-123" would share the same key.
- Value: The actual event payload, typically containing business data. This might be a JSON object describing a purchase, an Avro record of a sensor reading, or any serialized data format.
- Timestamp: When the event occurred. Event streams typically support two timestamp types: the time when the event was created (event time) and when it was written to the stream (ingestion time).
- Headers: Key-value metadata about the event, such as correlation IDs for tracing, content type information, or application-specific metadata that doesn't belong in the value. For practical guidance on leveraging headers, see Using Kafka Headers Effectively.
- Metadata: System-generated information like partition number, offset (position in the stream), and checksum for integrity verification.
This structure allows consumers to process events intelligently, filtering by headers, ordering by timestamp, or grouping by key, without parsing the entire value payload.
Core Characteristics of Event Streams
Event streams have several defining characteristics that distinguish them from other data systems:
- Immutable: Once an event is written to the stream, it cannot be modified or deleted (except by retention policies). This immutability provides a reliable audit trail and enables time-travel debugging.
- Append-only: New events are always added to the end of the stream. This simple write pattern enables extremely high throughput, streaming platforms like Kafka can handle millions of events per second on commodity hardware.
- Ordered: Events within a partition are strictly ordered. This ordering guarantee is critical for maintaining consistency. If a user creates an account and then updates their profile, consumers will always see these events in the correct sequence.
- Partitioned: Event streams are divided into partitions for parallelism and scalability. Each partition is an independent, ordered sequence. Partitioning allows horizontal scaling: more partitions mean more parallel consumers and higher throughput. For guidance on choosing partition keys and strategies, see Kafka Partitioning Strategies and Best Practices.
These characteristics make event streams ideal for distributed systems where multiple services need access to the same events without coordination or locking.
Producers, Consumers, and Decoupled Communication
Event streams enable a powerful pattern: decoupled, asynchronous communication between services.
- Producers are applications or services that write events to streams. A producer doesn't know or care who consumes its events. An e-commerce checkout service might produce "OrderPlaced" events without knowing whether they'll be consumed by an inventory service, an email service, or a fraud detection system.
- Consumers read events from streams independently. Each consumer maintains its own offset (position in the stream), allowing it to:
- Process events at its own pace
- Replay events from any point in time
- Fail and recover without affecting other consumers
- Join or leave without coordination
For detailed coverage of consumer mechanics and consumer groups, see Kafka Consumer Groups Explained and Kafka Producers and Consumers.
This decoupling provides enormous flexibility. You can add new consumers to react to existing events without modifying producers. If your fraud detection service goes down, it can resume processing from where it left off without losing data.
Consider a real-world example: ride-sharing applications. When a ride is completed, the mobile app produces a single "RideCompleted" event containing ride details. This event flows to multiple independent consumers: the billing service calculates charges, the rating service prompts for feedback, the analytics service updates driver performance metrics, and the data warehouse ingests it for reporting. Each service operates independently, and adding new functionality requires only adding a new consumer.
Event Stream Platforms and Technologies
Several platforms implement event streaming with different trade-offs:
- Apache Kafka is the most widely adopted event streaming platform. Kafka organizes events into topics (logical streams) divided into partitions. It provides strong ordering guarantees, configurable retention, and a rich ecosystem of connectors and stream processing tools. Kafka excels at high throughput and is commonly used for log aggregation, real-time analytics, and event-driven microservices. As of Kafka 4.0 (2024), Kafka runs in KRaft mode by default, removing the ZooKeeper dependency for simpler operations and improved scalability. For detailed information on Kafka's core architecture, see Kafka Topics, Partitions, and Brokers.
- Apache Pulsar is a newer alternative that separates compute and storage layers, enabling independent scaling. Pulsar topics support both streaming and queuing semantics, making it versatile for different use cases. Its multi-tenancy features make it attractive for service provider scenarios.
- AWS Kinesis is a fully managed streaming service in AWS. Kinesis streams provide similar functionality to Kafka topics but with tight integration into the AWS ecosystem. Organizations already on AWS often choose Kinesis for its operational simplicity, though it has lower throughput limits per shard compared to Kafka partitions.
- Azure Event Hubs and Google Cloud Pub/Sub provide similar managed streaming capabilities in their respective cloud ecosystems.
While these platforms differ in implementation details, they all provide the core event streaming primitives: durable, ordered, partitioned logs of events with independent consumer offsets. For understanding Kafka's modern architecture without ZooKeeper, see Understanding KRaft Mode in Kafka.
Architectural Patterns and Use Cases
Event streams enable several powerful architectural patterns:
- Event Sourcing stores all changes to application state as a sequence of events. Instead of storing current account balances, you store "MoneyDeposited" and "MoneyWithdrawn" events. The current balance is computed by replaying events. This provides perfect audit trails and enables time-travel queries: "What was this account's balance on March 15th?" For reliable event publishing patterns, see Outbox Pattern for Reliable Event Publishing.
- CQRS (Command Query Responsibility Segregation) separates write and read models. Commands produce events to the stream, and multiple read models (materialized views) are built by consuming those events. This allows optimizing each read model for specific query patterns without compromising the write model.
- Event-Driven Architecture builds systems as loosely coupled services that communicate through events. Services react to events rather than making direct API calls, reducing dependencies and improving resilience. For comprehensive coverage of this pattern, see Event-Driven Microservices Architecture.
Event streams are foundational to modern data architectures:
- Lakehouse architectures consume event streams from operational systems, landing events in object storage (like S3) for analytics while also serving real-time queries. For detailed coverage, see Introduction to Lakehouse Architecture and Streaming Ingestion to Lakehouse.
- Data Mesh uses event streams as the interoperability layer between domain-specific data products, enabling decentralized data ownership with centralized discoverability.
- Real-time analytics processes event streams as they arrive, powering dashboards, alerting, and automated responses with sub-second latency. See Real-Time Analytics with Streaming Data for implementation patterns.
Consider a financial services example: a trading platform produces trade execution events to a stream. One consumer updates user portfolios in real-time (CQRS read model), another feeds a risk management system, another lands events in a data lake for regulatory reporting, and a stream processing application detects suspicious trading patterns. All from a single event stream, with each consumer operating independently.
Schema Evolution, Retention, and Governance
As event streams become central to data architectures, managing their evolution and governance becomes critical.
- Schema Management: Event schemas evolve as businesses change. You might add new fields to capture additional information or deprecate old fields. Schema registries enforce compatibility rules: consumers can read events produced with newer or older schemas without breaking. Common strategies include forward compatibility (new consumers read old events), backward compatibility (old consumers read new events), and full compatibility (both directions). For detailed guidance on schema evolution strategies, see Schema Registry and Schema Management and Schema Evolution Best Practices.
- Retention Policies determine how long events remain in the stream. Short retention (hours or days) suits transient events like application logs. Long retention (months or years) enables reprocessing historical data. Infinite retention is common for event sourcing where events are the source of truth.
- Log Compaction provides an alternative to time-based retention. In a compacted topic, the stream retains only the latest event for each key. This is perfect for change data capture: you keep the current state of each database row without storing every historical change. For an in-depth explanation of log compaction mechanics, see Kafka Log Compaction Explained.
- Governance Challenges emerge as event streams scale:
- Discovery: Which streams exist? What events do they contain? Who produces and consumes them?
- Access Control: Who should be allowed to read or write specific topics?
- Data Quality: Are events conforming to expected schemas? Are critical fields populated?
- Compliance: Which streams contain sensitive data requiring encryption or access logging?
Modern governance platforms like Conduktor provide centralized visibility across Kafka clusters, showing consumer lag and data flows. These platforms enforce schema validation, manage access controls through policies rather than low-level ACLs, and provide data quality monitoring to detect anomalies in event streams. Conduktor Gateway, a Kafka proxy, adds an additional layer for testing scenarios including chaos engineering and protocol validation. For organizations running multiple Kafka clusters across teams, self-service capabilities ensure consistent policies and visibility without requiring every team to become Kafka experts. For more on monitoring, see Kafka Cluster Monitoring and Metrics.
Summary
Event streams represent a fundamental shift in how we build data systems — from storing state to recording facts, from synchronous coupling to asynchronous flow, from batch processing to continuous processing.
Key concepts:
- Event streams are immutable, ordered, partitioned logs of events, distinct from both databases and message queues
- Each event carries structured data (key, value, timestamp, headers) with system metadata
- Producers and consumers are decoupled, enabling independent scaling and flexible architectures
- Platforms like Kafka (KRaft mode in 4.0+), Pulsar, and Kinesis provide different implementations with similar core primitives
- Architectural patterns like event sourcing and CQRS leverage event streams to build auditable, scalable systems
- Modern data architectures — lakehouses, data mesh, real-time analytics — rely on event streams as their foundation
- Schema evolution, retention policies, and governance tools are essential as event streaming scales
Related Concepts
- Kafka Topics, Partitions, and Brokers: Core Architecture - Deep dive into Kafka's foundational components for event streaming
- Event-Driven Architecture - Architectural patterns built on event streams
- Streaming Data Pipeline - Building end-to-end pipelines with event streams
Sources and References
- Kleppmann, Martin. Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems. O'Reilly Media, 2017. (Chapters on Replication, Partitioning, and Stream Processing)
- Kreps, Jay. "The Log: What every software engineer should know about real-time data's unifying abstraction." LinkedIn Engineering Blog, December 2013. https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
- Apache Kafka Documentation. "Introduction to Kafka Streams." Apache Software Foundation. https://kafka.apache.org/documentation/streams/
- Stopford, Ben. Designing Event-Driven Systems: Concepts and Patterns for Streaming Services with Apache Kafka. O'Reilly Media, 2018.
- AWS Documentation. "What Is Amazon Kinesis Data Streams?" Amazon Web Services. https://docs.aws.amazon.com/streams/latest/dev/introduction.html
- Narkhede, Neha, Gwen Shapira, and Todd Palino. Kafka: The Definitive Guide. O'Reilly Media, 2017.